

AI 编程从插件走向生产线
前几天我看一个 AI Agent 改代码的视频,差点把自己看笑了。
需求只有一句:“给后台加一个导出 CSV。”它很兴奋,立刻开写,十几个文件一顿改,接口、按钮、状态、测试全都给你安排上。看起来特别勤奋,像一个刚入职但精力旺盛到吓人的实习生。
我意识到:它根本没问清楚“导出谁、按什么筛选导出、谁有权限导出、数据量大怎么办”。
这就是现在 AI 编程最容易被低估的风险:AI 不是不会写代码,而是太会写代码了。
它可以把一个模糊想法迅速变成一堆看起来完整的实现。但真实项目里,真正贵的从来不是“写出代码”,而是:需求有没有对齐,边界有没有想清楚,测试有没有先定义,发布前有没有验收。
所以今天这篇文章,不讲“再装一个更强插件”。
我们讲一套更像工程生产线的组合:OpenSpec + Superpowers + gstack。
它们分别管住 AI 编程的三个关键环节:
• OpenSpec:写代码前,把需求锁住 • Superpowers:写代码时,用 TDD 和工程纪律卡住质量 • gstack:写完代码后,用评审、QA、发布流程把交付包起来 |
如果只装一个工具,你得到的是一个更强的 AI 助手。
但如果把这三个工具串起来,你得到的更像是一条从想法到上线的 AI 软件生产线。
先说结论:它们不是一类工具
很多人第一次看到 OpenSpec、Superpowers、gstack,会把它们都归到“Claude Code 插件”“Skills”“工作流增强”里。
这就像把产品经理、测试工程师、发布经理都叫成“写文档的人”。听着没错,实际完全不是一回事。
这三个工具真正的分工是:
• OpenSpec:负责需求、规范、验收标准,是需求真相源 • Superpowers:负责 TDD、计划、代码审查纪律,是质量门禁 • gstack:负责多角色评审、浏览器 QA、发布,是交付编排器 |
换句话说:
OpenSpec 负责“不写偏”,Superpowers 负责“不乱写”,gstack 负责“不假装交付”。
这句话基本就是整套组合的核心。

OpenSpec、Superpowers、gstack 的三层分工
OpenSpec:先把需求从聊天记录里拎出来
AI 编程第一个大坑,是需求经常只存在聊天记录里。
你说:“帮我加一个暗色模式。”
AI 说:“好的,我来实现。”
然后它就开始写了。
但真实需求里藏着一堆问题:
• 是跟随系统,还是手动切换? • 要不要记住用户选择? • SSR 场景怎么办? • 是否影响已有主题变量? • 哪些页面必须覆盖? • 验收标准是什么? |
如果这些问题没有被固定下来,AI 写得越快,偏得也可能越快。
OpenSpec 的价值就在这里:在第一行代码出现之前,先把想法变成可审查、可追踪、可归档的规范文件。
一个标准变更通常会生成这些产物:
openspec/changes/add-user-export/ proposal.md design.md tasks.md specs/ user-export.md |
它们分别回答:
• proposal.md:为什么做、要解决什么问题 • specs/:系统应该表现出什么行为,验收场景是什么 • design.md:技术上打算怎么实现 • tasks.md:拆成哪些可执行步骤 |
注意,OpenSpec 不是为了让 AI 写得更快。
它是为了让 AI 不要一上来就写偏。
这也是我现在最建议团队建立的习惯:只要是生产功能,不要从“写代码”开始,从“变更规范”开始。
Superpowers:把“写高质量代码”变成硬规则
第二个坑,是 AI 很容易跳过工程纪律。
人类工程师写功能,至少会经历几个动作:想边界、拆任务、写测试、做实现、跑验证、看 diff。
AI 的默认倾向却是:先写实现,再补一段“已完成,测试通过”。
听起来很熟悉吧?有时候它甚至测试都没跑,只是气势跑满了。
Superpowers 的思路不是对 AI 说一句“请写高质量代码”。这种话太虚了,和对自己说“明天开始早睡”差不多。
它是把工程方法论拆成一组可触发的 Skills,让 AI 在不同阶段自动进入对应流程,比如:
• 需求澄清 • 头脑风暴 • 写实现计划 • Git worktree 隔离开发 • 测试驱动开发 • 子代理执行任务 • 代码审查 • 修复审查反馈 • 完成分支并准备合并 |
这里最关键的是 TDD。
Superpowers 里的 TDD 不是“最好写点测试”。它更接近一条硬门禁:
RED → GREEN → REFACTOR |
也就是:
1. 先写失败测试 2. 确认测试真的失败 3. 写最小实现 4. 确认测试通过 5. 再重构 |
如果 AI 先写实现,再补测试,这不叫 TDD。
因为那种测试很容易变成“证明已有代码没错”,而不是“定义正确行为”。
在 AI 编程里,测试还有一个更重要的作用:测试是给 AI 的可执行规格说明。
自然语言 specs 可能会有歧义,测试不会。
比如“用户导出 CSV”这个功能,后端测试可以先定义:
- 非 admin 用户调用导出 API 返回 403- admin 用户调用导出 API 会创建 export job- 导出结果只包含当前筛选条件下的用户- CSV 不能包含未授权字段 |
这些测试一旦先写出来,AI 就不再是在“自由发挥”。
它是在沿着轨道施工。

Superpowers 用 TDD 卡住编码质量
gstack:代码写完,不等于真的交付
第三个坑,是“代码能跑”经常被误当成“已经交付”。
真实项目里,完成一个功能远不止提交代码。
你还要确认:
• 产品上是否值得做 • 范围有没有失控 • 架构是否合理 • 用户体验是否清楚 • diff 有没有安全问题 • 浏览器里是否真的能走通 • 发布前检查是否完成 • PR 描述是否说清楚 |
gstack 的特点,是把 Claude Code 变成一个小型虚拟工程团队。
它提供了很多角色化命令,例如:
/office-hours/plan-ceo-review/plan-eng-review/plan-design-review/plan-devex-review/review/qa/ship/retro |
这些命令不是为了“多套一层仪式感”。
它们是在逼 AI 从不同角色重新看一遍这个功能。
CEO/产品视角会问:这个功能真的值得做吗?有没有更小的版本?
工程视角会问:会不会拖垮数据库?权限校验在哪里?失败状态怎么处理?
设计视角会问:用户点击后看到什么?处理中怎么反馈?空结果怎么办?
DevEx 视角会问:API 命名清楚吗?测试好写吗?以后扩展别的导出类型麻烦吗?
这就是 gstack 在这套组合里的位置:它不是帮你写某段代码,而是把“从想法到发布”的流程编排起来。
为什么三个工具可以同时装?
关键原因很简单:它们不抢同一个位置。
OpenSpec 的核心状态在:
openspec/ changes/ your-change/ proposal.md design.md tasks.md specs/ |
它关心的是“这个功能的规范是什么”。
Superpowers 更偏 agent 方法论和 Skills,通常通过:
CLAUDE.md.claude/skills/ |
把 TDD、计划、审查等工程纪律注入 AI 编程环境。
gstack 则有自己的技能目录、命令、浏览器能力和流程状态,通常围绕:
~/.claude/skills/gstack.gstack/CLAUDE.md 中的 gstack 配置 |
它关心的是“这个功能如何走完评审、QA、发布”。
所以它们不是互相覆盖,而是分层:
OpenSpec = 需求层Superpowers = 质量层gstack = 交付层 |
这也是为什么我更愿意把它们理解成一条生产线,而不是三个插件。
真正重要的不是安装,而是串联
很多教程会把重点放在安装命令上。
这当然有用,但不是最重要的。
真正有价值的是:一个功能从想法到上线,每一步如何自然触发下一步。
理想流程不是:用完 OpenSpec,手动切到 Superpowers,再手动切到 gstack。
更好的状态是它们在同一个 Claude Code 会话里共同生效:
1. 你正常输入需求 2. OpenSpec 先生成规范 3. gstack 读取规范做计划评审 4. 编码阶段 Superpowers 的 TDD hard gate 生效 5. 代码完成后 gstack Review 和 QA 接管 6. 发布完成后 OpenSpec Archive 归档规范 |
这才是一条闭环。
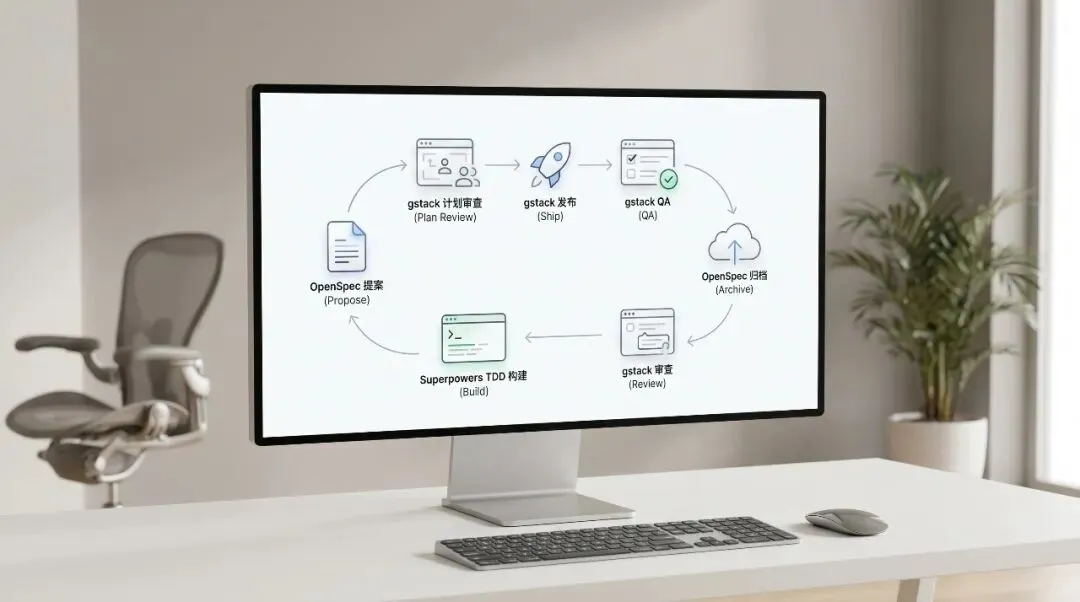
从想法到上线的 AI 编程闭环
一个完整例子:给后台增加“用户批量导出 CSV”
假设我们要做一个功能:给后台系统增加“用户批量导出 CSV”。
不要直接说“帮我实现”。
第一步应该是让 OpenSpec 生成需求产物:
/opsx:propose add-user-export |
然后补充一段稍微完整的需求:
我们要给后台用户管理页增加批量导出 CSV 功能。 目标: - 管理员可以按当前筛选条件导出用户列表 - 导出字段包括用户 ID、邮箱、昵称、注册时间、状态 - 导出需要受权限控制,只有 admin 可以使用 - 大数据量不能阻塞主请求 - 前端需要显示导出进度或至少显示导出任务状态 - 导出文件有效期 24 小时 请先生成 proposal、specs、design、tasks,不要开始写代码。 |
这里的重点是最后一句:不要开始写代码。
你要先检查 proposal 是否讲清楚为什么做,specs 是否写清楚验收标准,design 是否只是实现设计而不是重写需求,tasks 是否拆到 AI 可以稳定执行。
一个好的验收场景应该像这样:
场景:管理员导出当前筛选结果Given 管理员在用户管理页选择状态为 active 的筛选条件When 点击导出 CSVThen 系统应创建导出任务And 导出的 CSV 只包含 active 用户And CSV 包含用户 ID、邮箱、昵称、注册时间、状态字段 |
接着,不要急着开写,让 gstack 读取这些产物做评审:
请读取 openspec/changes/add-user-export/ 下的 proposal、specs、design、tasks,然后用 gstack 的评审流程检查这个方案。 |
可以依次触发:
/plan-ceo-review/plan-eng-review/plan-design-review/plan-devex-review |
评审结束后,让 AI 把问题合并成一个修订清单,并且只修改 OpenSpec 产物,不写代码。
等方案真的稳定了,再进入 Superpowers TDD:
接下来按照 Superpowers 的 TDD 流程执行。先根据 OpenSpec specs 和 tasks 写失败测试。不要先写实现代码。每个任务都遵守 RED-GREEN-REFACTOR。 |
代码完成后,用 gstack Review 看 diff:
/review |
Review 的输入应该同时参考:OpenSpec specs、tasks、Superpowers 生成的测试、当前分支 diff、项目已有代码风格。
如果发现问题,不要让 AI 一口气全改。
更稳的方式是:
请按严重程度排序。先修 Critical 和 High。每次只修一类问题。修完后重新跑相关测试。 |
最后进入浏览器 QA:
/qa |
这个功能至少要验证:
• admin 可以导出当前筛选条件下的用户 CSV • 非 admin 不能导出 • CSV 字段正确 • 空结果状态正确 • 导出失败时有错误提示 • 重复点击不会创建一堆异常任务 |
Review 看的是代码,QA 看的是用户路径。
这两个不能互相替代。
推荐的实战命令顺序
如果你只想照着跑,可以用下面这套顺序。
第一阶段,生成需求规范:
/opsx:propose add-user-export |
补充要求:
请生成 proposal、specs、design、tasks。不要开始实现。specs 里必须包含权限、筛选条件、大数据量、失败场景、CSV 字段验收。 |
第二阶段,计划评审:
请读取 openspec/changes/add-user-export/ 下的所有产物,基于这些产物进行 gstack 计划评审。 |
然后依次执行:
/plan-ceo-review/plan-eng-review/plan-design-review/plan-devex-review |
第三阶段,TDD 实现:
现在根据已确认的 OpenSpec 产物开始实现。必须遵守 Superpowers TDD:1. 先写失败测试2. 看到测试失败3. 写最小实现4. 看到测试通过5. 重构6. 每完成一个 task 就提交或至少给出 diff 摘要 |
第四阶段,代码审查:
/review |
第五阶段,浏览器 QA:
/qa |
第六阶段,发布:
/ship |
发布前确认:
- tests 通过- lint/typecheck 通过- review 问题已关闭- QA 通过- PR 描述包含 OpenSpec 变更摘要 |
第七阶段,归档:
/opsx:archive add-user-export |
注意顺序:先 Ship,后 Archive。
Archive 是规范归档,不是发布动作。
最容易踩的 6 个坑
第一,重复门禁。
不要让三个工具审同一件事。更好的分工是:OpenSpec 定义需求,gstack 从角色视角评审计划,Superpowers 卡编码纪律,gstack 再审查代码、QA、发布,最后 OpenSpec 归档规范。
第二,把 gstack 设计文档当成需求真相源。
在这套组合里,Specs 才是唯一真相源。如果 gstack 评审发现需求问题,应该回头修改 OpenSpec 产物,而不是直接改实现。
第三,把 Archive 当发布。
OpenSpec Archive 只是规范归档。真正的发布出口应该是:
/ship |
第四,TDD 只做形式。
先实现再补测试,不叫 TDD。真正的 TDD 必须看到测试先失败。
第五,让 AI 一次性修所有 Review 问题。
Review 后如果有 20 个问题,不要直接说“全部修复”。先修 Critical,跑测试;再修 High,跑测试;Medium 和 Low 单独判断。
第六,QA 只测 happy path。
真实问题通常出在异常路径。至少要覆盖权限不足、空数据、网络失败、超大数据、重复点击、任务处理中刷新页面、导出文件过期、接口返回错误。
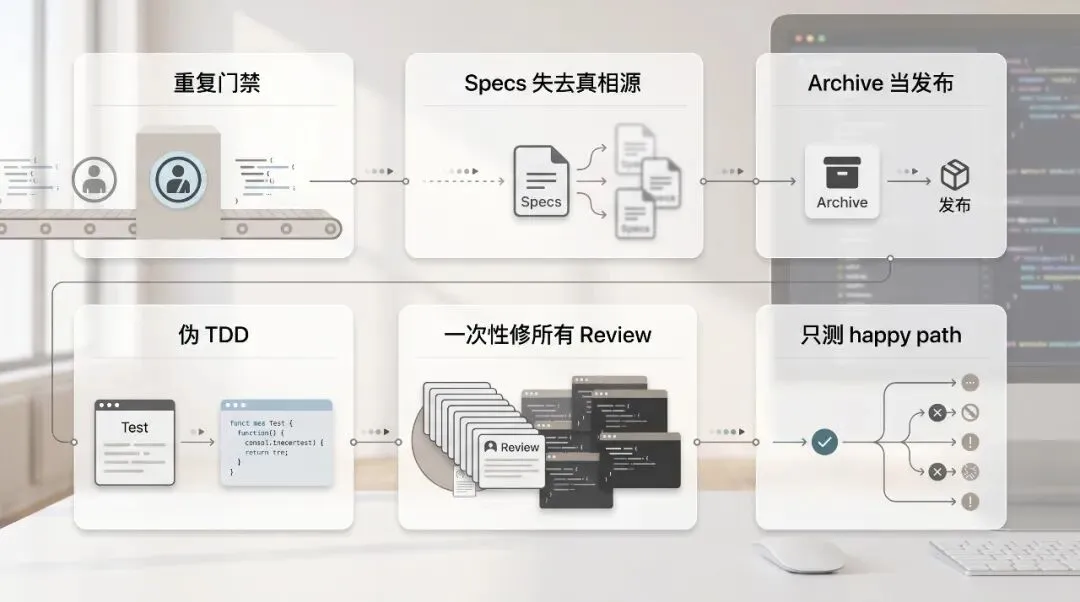
AI 编程生产线最容易踩的六个坑
什么时候可以跳过 TDD?
Superpowers 强调 TDD,但不是所有场景都值得完整 TDD。
我一般只在三类场景里放松:
• 一次性原型:当天验证 Demo,代码之后会丢弃 • 生成代码:API client、schema types、迁移产物等由上游 schema 保证 • 配置文件:比如 eslint 配置、环境变量示例、文档配置,可以用验证命令替代 TDD |
除此之外,只要是生产功能,尤其涉及数据、权限、支付、任务队列、状态流转,都建议严格执行 TDD。
别嫌麻烦。
AI 写代码越快,流程越不能省。
这套组合适合谁?
它适合这些人:
• 已经在用 Claude Code 做真实项目的人 • 想把 AI 编程从 vibe coding 升级成工程流程的人 • 独立开发者、小团队、技术创始人 • 需要频繁做功能迭代的 SaaS 或工具产品 • 对质量、测试、发布有要求的生产项目 |
它不太适合这些场景:
• 只想让 AI 改一行 CSS • 纯玩具 Demo • 完全不想维护测试 • 没有 Git 流程 • 不愿意审查 AI 输出 |
这套组合不是为了让你少思考。
恰恰相反,它是为了让你的思考被结构化,然后交给 AI 稳定执行。
最后的心法:不要把 AI 当写代码机器
没有流程时,AI 像一个很会写代码的实习生。
你说什么,它写什么。你没说的,它自己猜。你不检查,它就默认完成。
有流程后,AI 才像一个可管理的工程团队。
OpenSpec 先问清楚需求。
Superpowers 要求它按 TDD 写代码。
gstack 让它接受产品、工程、设计、QA、发布多轮检查。
最后 OpenSpec 再把规范归档,成为下一次迭代的上下文。
所以这套组合的核心不是:
装了三个工具。 |
而是:
搭了一条从需求到发布的 AI 工程流水线。 |
一句话总结:
OpenSpec 在写代码前把需求锁住,Superpowers 在写代码时把质量卡住,gstack 在写完代码后把交付包住。
这才是 AI 编程从“能用”走向“可上线”的关键。
