
现在,所有公司都在想同一个问题:
为什么我的 token 够用、用最好的模型,但还是不能把 AI coding 放到生产线里面去?
答案通常不在模型。同一个模型,只换外面包裹的那层"壳",编程基准的成功率就能从 42% 跳到 78%。这层壳,有了一个正式的名字:Harness。
01
一个公式:coding agent = AI model + harness
模型是 CPU,Harness 是操作系统。CPU 再强没有操作系统也跑不起来。
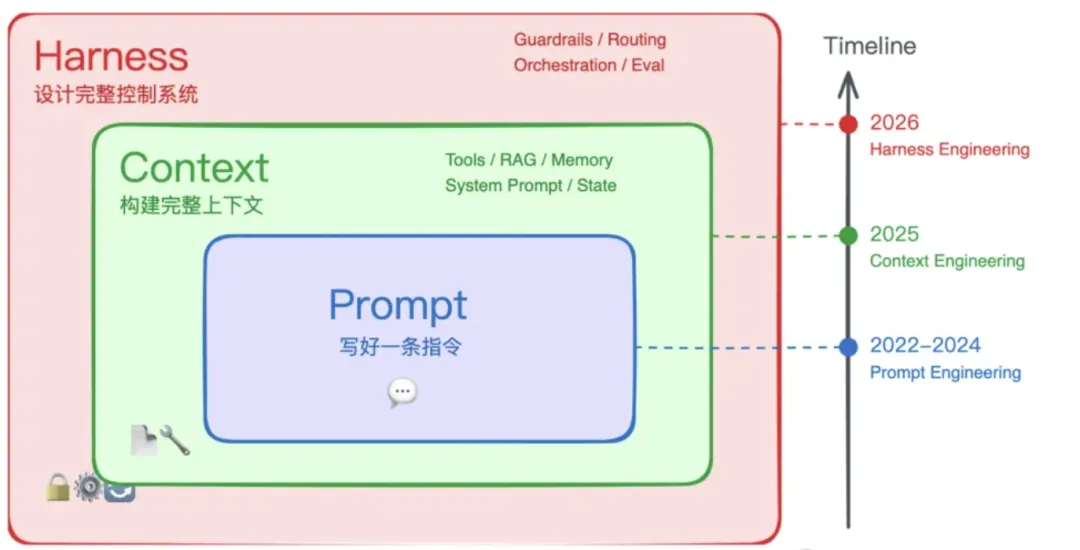
拆开来看,Harness 由五层构成:
Harness = Tools + Knowledge + Observation + Action + Permissions
Harness = 工具 + 知识 + 观测 + 操作接口 + 权限Tools 文件读写、Shell、网络、数据库、浏览器 ——给模型双手Knowledge 产品文档、领域资料、API 规范、风格指南 ——给模型背景Observation git diff、错误日志、浏览器状态、传感器数据 ——给模型眼睛Action CLI 命令、API 调用、UI 交互 ——给模型出口Permissions 沙箱隔离、审批流程、信任边界 ——给模型护栏
五层缺一不可。缺了 Tools 模型只能空想,缺了 Observation 它执行完一步不知道发生了什么,缺了 Permissions 迟早在生产环境翻车。
02
Knowledge 不是把所有文档一股脑塞进 prompt,而是按需加载。这就是 Skills 解决的问题。
Skills 是专门的 prompt 模板,在被调用时注入对话上下文,同时修改工具权限。模型通过推理而非算法匹配来决定何时调用哪个 Skill——它知道有什么可以用,但只有任务真正需要时才取。
实践中,一个成熟的 Harness 可以挂载 100+ 个 Skill,但每个 Skill 在未被触发时不消耗任何 context token。一个前端 Skill 让模型输出有设计感的组件而不是千篇一律的模板;一个数据库 Skill 让它自动写出带索引的查询而不是 SELECT *。区别不是模型变聪明了,是 Knowledge 层给了它该有的上下文。
ETH Zurich 的研究发现,AGENTS.md 文件应该控制在 60 行以内。过长的指令文件反而会降低 Agent 表现。写"目录",不要写"百科全书"。
03
OpenClaw? 就是一个本地运行的 agentic harness,通过 WhatsApp、Telegram 等消息应用接收指令,连接多个模型 API,在后台自主执行任务。它的架构把五层拆得很清晰:Tools 层负责调工具,Knowledge 层挂 Skills,Observation 层收集执行结果,Action 层输出命令,Permissions 层控制哪些操作需要人工审批、哪些可以直接执行。
你可以告诉它"清理收件箱里的垃圾邮件"或者"把最新 commit 部署到 staging",它在你睡觉时跑完。表面上看是一个好用的工具,本质上是五层 Harness 的完整实现。
Peter Steinberger 推出 OpenClaw 项目后 4 个月拿到 18 万 stars,成了 GitHub 上增长最快的仓库。
他不逐行审查 Agent 生成的代码。在他看来,审查应该变成"prompt review"——关心的是生成代码的提示词写得好不好,而不是代码本身长什么样。
他还发现了一个反常识的现象:喜欢算法谜题的工程师反而很难适应 Agent 工作流,产品导向的工程师适应得更快。
04
大多数人搭 Harness 时会认真设计 Tools 和 Knowledge,但 Permissions 往往是事后补丁。
Claude Code 的 hook 系统和各类 harness 的信任边界验证,本质上是在模型概率性决策的外围建立一道确定性防火墙。模型可以决定"我要删这个文件",但 Permissions 层决定这个操作是直接执行、还是先暂停等你确认。
生产环境里,Permissions 层的缺失往往才是 AI coding 翻车的真正原因,不是模型不够聪明。
Vercel 把 Agent 的工具从 15 个砍到只剩 2 个,准确率反而从 80% 升到 100%。Stripe 有 500 个 MCP 工具挂在平台上,但给每个 Agent 的只是精心筛选过的子集。更多工具不等于更好表现,约束解空间反而让 Agent 更快收敛到正确答案。
Stripe 还有一条硬性规定:CI 最多跑两轮。第一轮失败,Agent 自动修复再跑一次;还失败,直接转交人类。不允许无限重试。
05
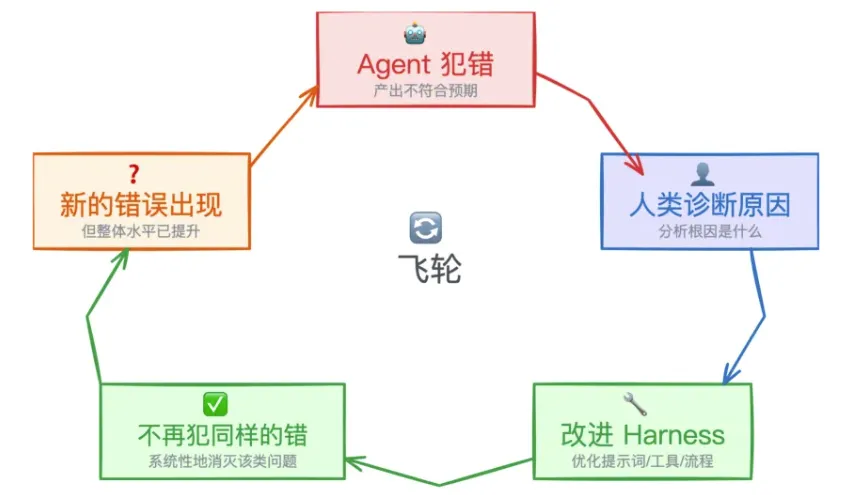
Mitchell Hashimoto 对 Harness Engineering 的定义只有一句话:
每当你发现 Agent 犯了一个错误,就花时间工程化一个解决方案,让它再也不会犯同样的错。
他的 AGENTS.md 文件里每一行规则,背后都对应着 Agent 曾经犯过的一个错。
这构成了一个持续改进的飞轮:
Agent 犯错 → 诊断原因 → 改进 Harness → 下次不再犯 → 新的错误出现 → 循环继续。
OpenAI Codex 团队用这套方法,5 个月、3 名工程师、零行手写代码,产出了 100 万行生产级代码。他们对自己工作的描述是:我们不写代码,我们写规则。
你在做的事,
不叫 prompt engineering,
叫 harness engineering。
模型够聪明了。
它只是缺一个舒适的家?。
往期回顾:
