
当大多数AI初创公司还在拼命融资"造大模型"的时候,一家成立不到3年的公司,靠"不做模型"拿到了20亿融资。
2026年6月,北京硅基流动科技有限公司宣布完成超20亿元B轮融资,跻身AI行业新锐阵营。投资方不是看中了它的模型能力,而是它的**"Token工厂"模式**——帮别人把算力变成Token,再把Token卖出去。
这家公司的打法,正在重塑整个AI产业的逻辑。
一家不做大模型的公司,怎么活?
硅基流动的核心业务,说白了就是AI产业的"中间层"。
上游,国内AI产业高度碎片化——模型有阿里、DeepSeek、智谱等上百款,算力芯片有英伟达GPU也有各类国产替代,彼此之间互不兼容。模型厂商不可能适配所有芯片,芯片厂商也不可能跑通所有模型。大量算力资源长期闲置,企业接入AI的成本高得离谱。
硅基流动做的事,就是填平这个鸿沟。它搭建了一个兼容160余款主流AI模型的云服务平台,通过自研推理引擎和算力调度系统,让不同模型在不同芯片上都能高效运行。把零散的算力,变成标准化的Token服务,卖给需要用AI的企业。
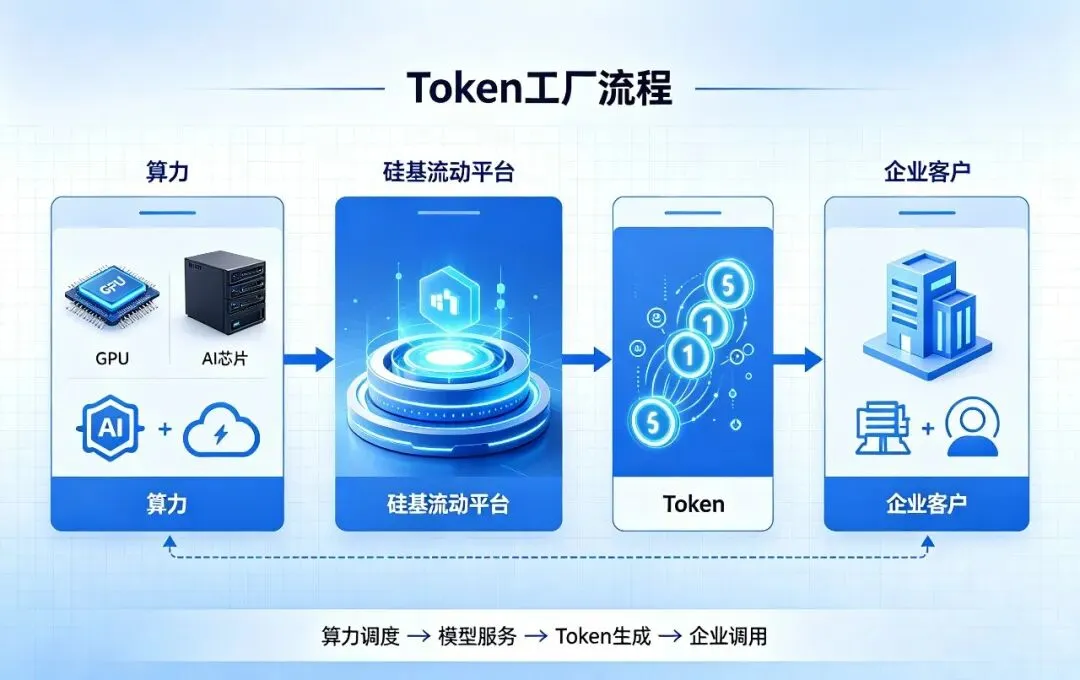
不做大模型,不和OpenAI、Anthropic竞争,也不和阿里、字节正面PK。它的定位是:所有模型商的服务商,所有算力商的分发商。
数字说话:一年营收涨10倍
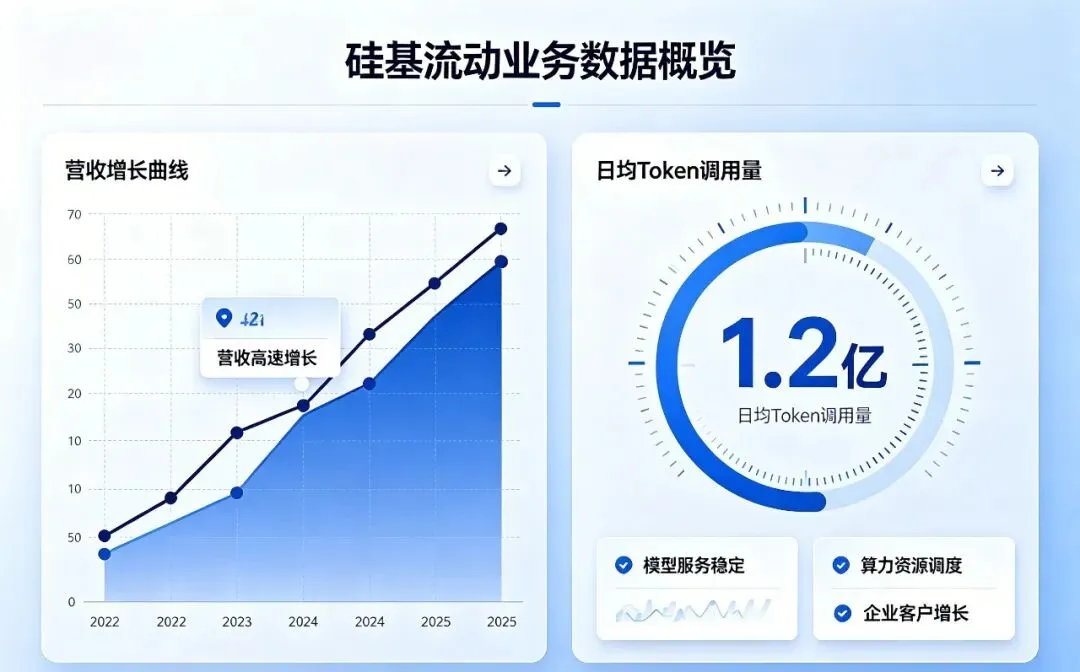
这个模式的成效,数据很亮眼:
过去一年企业级业务营收同比涨幅超10倍 日均Token调用量达数万亿级别 累计服务万家企业客户 海外市场单月营收突破数百万美元
轻资产、高周转、按量付费。相比之下,专注造大模型的公司,每年研发投入几十亿,盈利周期遥遥无期。硅基流动的模式,已经被市场证明跑通了。
为什么资本现在疯狂押注"中间层"?
2024年到2025年,AI圈最热的是"大模型竞赛"——参数规模、评测分数、发布日期,所有人都在盯着模型本身。
但到了2026年,风向变了。
达沃斯论坛上,多位行业大佬给出了同一个判断:模型本身已经不是稀缺资源,能把模型用起来的"水、电、煤"才是。
中国移动首席科学家冯俊兰在达沃斯论坛上说了句话很直接:“我们投入大量资金建数据中心,但芯片的迭代没有减速。建一个数据中心,可能半年后新一代模型或AI芯片就会迭代两轮。你的投资可能会悄无声息地闲置在那里。”
这句话点出了AI产业的一个核心矛盾:技术迭代太快,但企业落地太慢。 中间的适配层、调度层、运维层,成了整个链条上最薄弱的环节。
硅基流动的"Token工厂"模式,恰恰填补了这个空白。它不赌单一模型的胜败,而是服务所有模型,让整个行业的水流得更顺畅。
欧洲人说:“中国在具身智能上让我们羡慕”
这周在辽宁大连举办的夏季达沃斯论坛,AI是绝对主角。
90多个国家和地区、1700余名嘉宾,百余场分论坛中,直接涉及AI的超过10场,涉及AI融合议题的超过30场。
有意思的是,今年达沃斯关于AI的讨论,已经完全脱离了"纯软件理论"的务虚阶段,所有人都在聊怎么落地、怎么赚钱。
多位欧洲机构负责人公开表示:中国在"物理AI"与"具身智能"方面已经走在前面。
荷兰国家数学与计算科学研究中心主任瓦妮莎·埃弗斯说:“与美国企业把巨额资金投入通用人工智能基础研发不同,中国更注重把AI整合进现有服务链条。中国为机器人技术提供了丰富的’试验场’,让新技术在真实场景中快速迭代。”
与此同时,中国完备的制造业供应链,正吸引全球资本加速布局。2025年,科技研究和技术服务领域新设外资企业1.4万家,同比增长27.2%。从"在中国生产"转向"在中国创造",已成大势。

这个赛道有没有风险?
当然有。
硅基流动的模式有一个根本性的挑战:巨头正在垂直整合。
OpenAI在自建算力,Google在推TPU云,国内阿里、字节、百度也都在搭建自己的"模型+算力+应用"闭环。如果巨头把中间层也自己做完了,硅基流动的生存空间就会受到挤压。
此外,MaaS赛道热度攀升,同质化竞争加剧,Token服务价格长期看存在下行压力,合规监管也在趋严。
但至少在今天,它的崛起证明了一件事:AI行业不是只有"造模型"一条路,"卖水"也能卖出大生意。
