
一、数据简介
解码企业"沉默策略",揭示披露差异的战略密码!
在日益激烈的市场竞争中,企业信息披露早已不再是简单的合规要求,而是关乎竞争优势与战略防御的关键博弈。尽管传统研究多聚焦于披露数量与披露质量,但企业如何通过内容策略“顾左右而言他”,在满足监管要求的同时保护专有信息,始终是学术研究中的重要盲区。
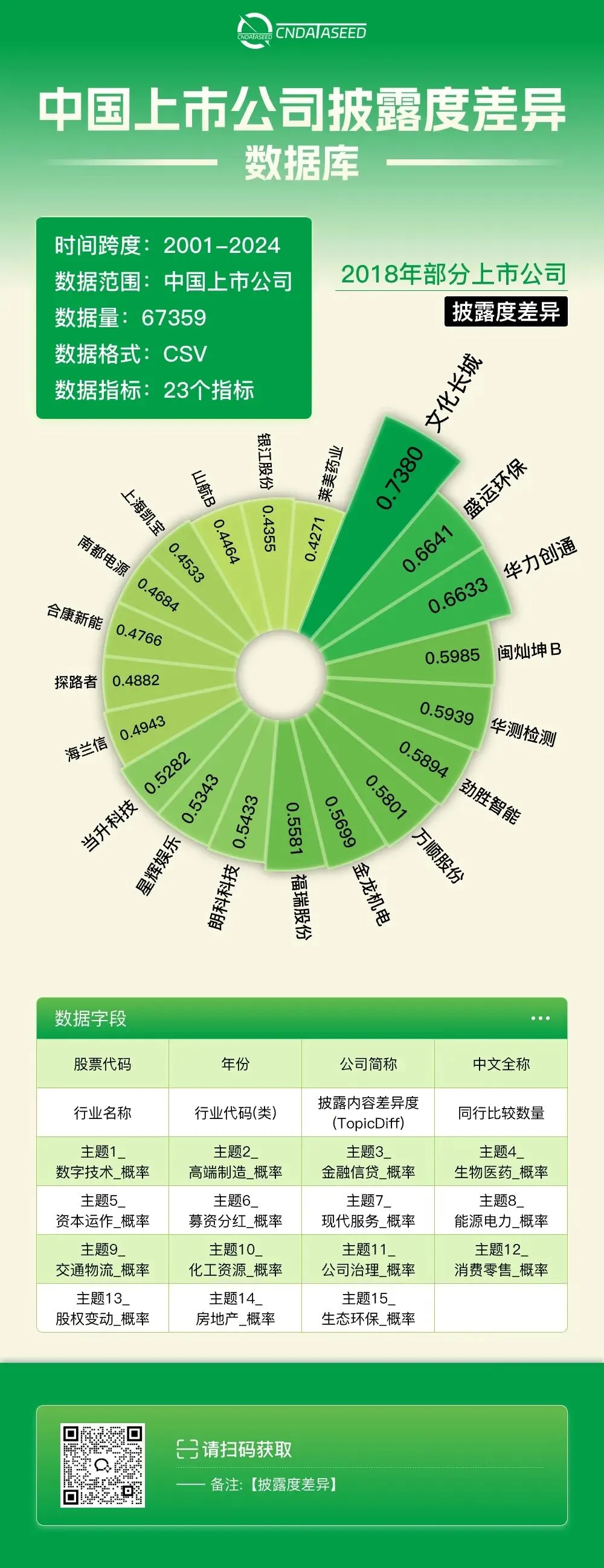
针对这一问题,CnDataSeed 团队基于 LDA 主题建模算法,构建了 《中国上市公司披露度差异数据库》。该数据库对企业年度报告等披露文本进行深度语义分析,将复杂的文本叙事转化为15 个战略主题的概率分布矩阵,并进一步通过 JS 距离计算披露内容差异度指标。数据库不仅系统捕捉企业在数字技术、高端制造、金融信贷等关键领域的披露偏好,还能够量化企业相对于同行的披露策略差异,为理解企业的竞争防御与信息博弈机制提供了独特的数据视角。
相较于传统财务指标,该数据库能够精准识别企业在竞争压力下的披露调整行为,有力支持研究者深入探索产品市场竞争、信息不对称治理、投资者关系管理以及 ESG 信息披露等前沿议题。研究者可利用该数据系统检验披露差异对融资成本、创新激励与股东价值的影响,量化分析企业如何通过主题分布优化在透明度与竞争保护之间取得平衡,实现从文本叙事到战略行为的深度映射。
凭借严谨的语义建模方法与可复现的量化指标体系,《中国上市公司披露度差异数据库》为中国企业信息生态研究提供了突破性的实证工具,助力学术创新与投资决策的精准洞察。现在获取这份数据,抢占披露策略研究的制高点。
二、数据概览
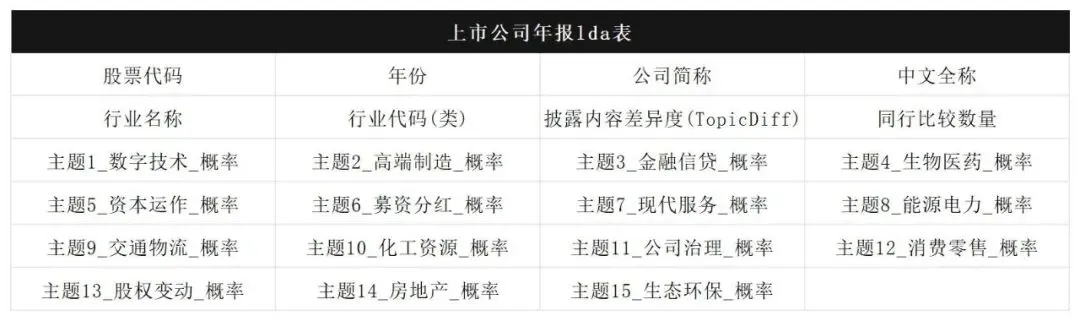
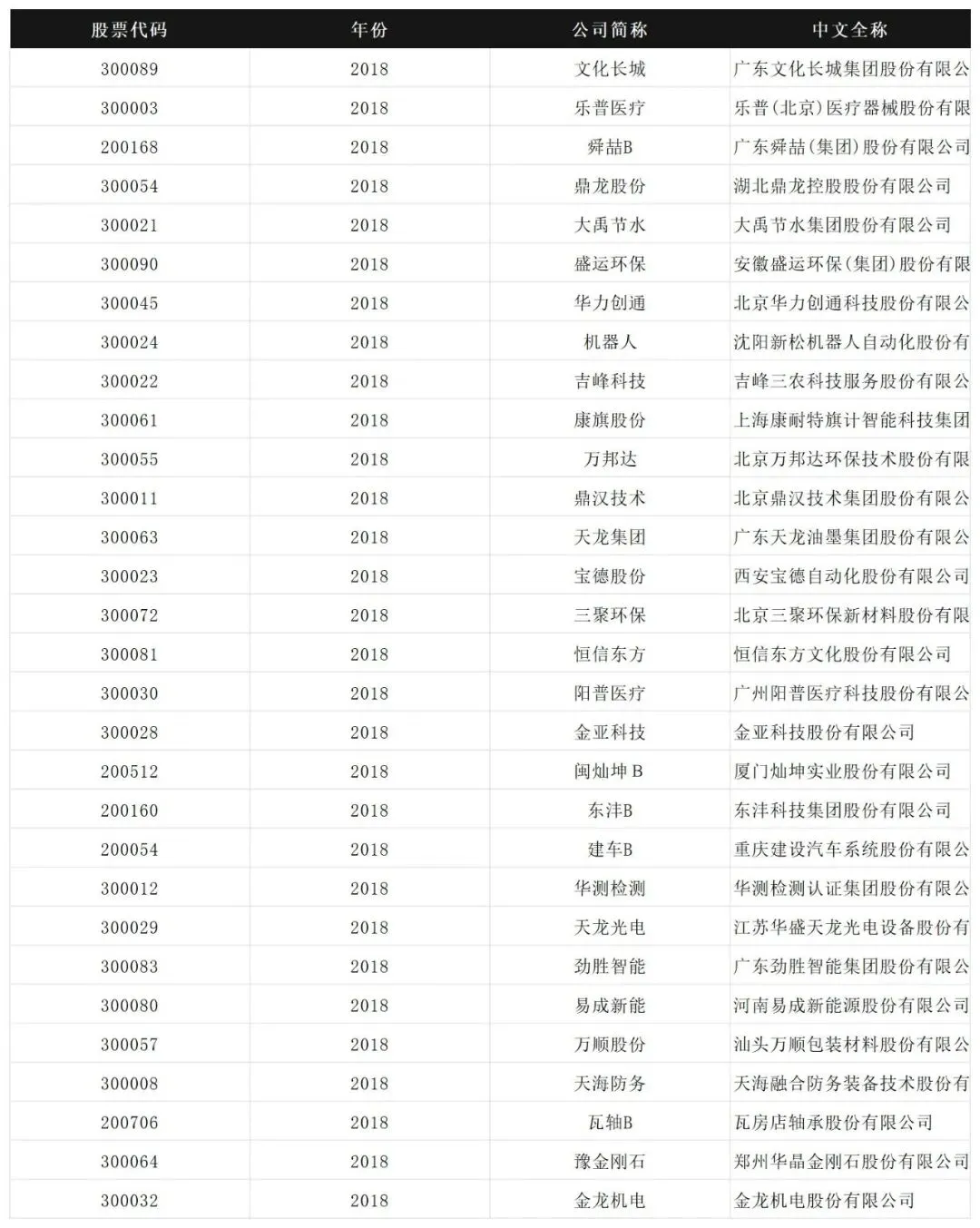
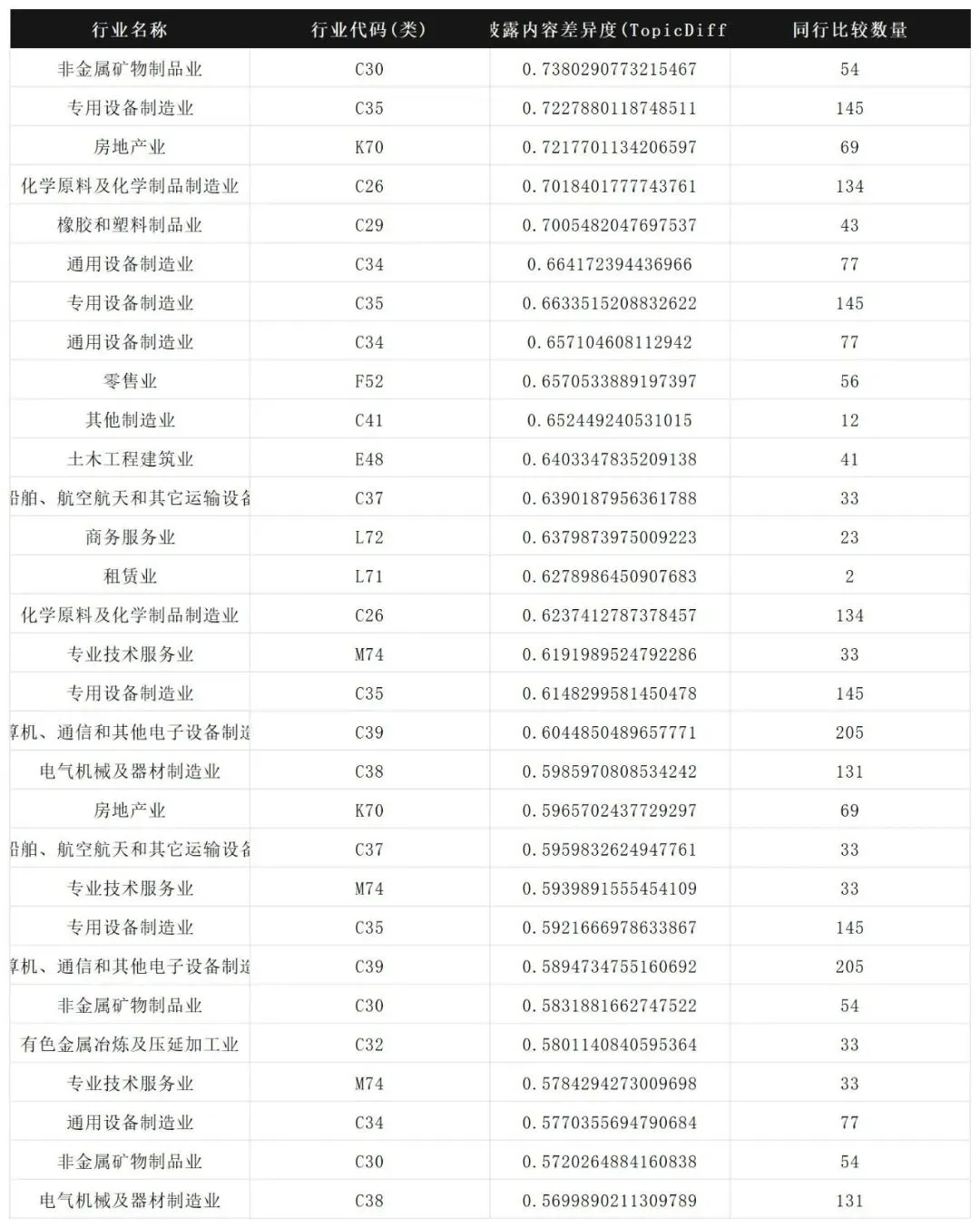
数据表格:




三、相关处理
基于 LDA 的披露主题识别与差异建模
在文本向量化的基础上,使用 LDA 主题模型识别企业披露中的潜在主题结构,将“披露内容差异”从定性文本转化为可比较的主题空间。
tf = CountVectorizer(max_df=0.90, min_df=10).fit_transform(df['cut_text'])lda = LatentDirichletAllocation(n_components=15, random_state=666)lda.fit(tf)披露内容的概率化刻画与公司层面量化
MD&A 文本映射到主题概率分布,形成“公司 × 主题”的结构化披露画像
doc_topic_dist = lda.transform(tf)final_df = pd.concat([df[['stkcd','year','firm_name']], pd.DataFrame(doc_topic_dist)], axis=1)四、相关研究
部分相关研究示例
Chu, Yongqiang, et al. "Product market competition and disclosure content differentiation: A topic modeling analysis." Journal of Business Finance & Accounting 52.2 (2025): 691-721.
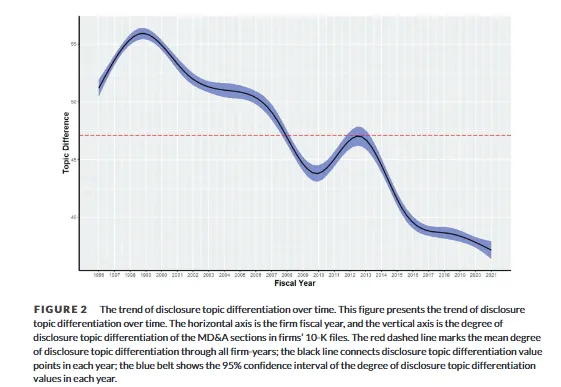
更多相关研究:
[1]Fengler M R, Phan T M. Unveiling themes in 10-K disclosures: A new topic modeling perspective[J]. International Review of Financial Analysis, 2025, 103: 104121.
[2]Rao, S.; Juma, N.; Srinivasan, K. Textual Analysis of Sustainability Reports: Topics, Firm Value, and the Moderating Role of Assurance. J. Risk Financial Manag. 2025, 18, 463. https://doi.org/10.3390/jrfm18080463
六、获取方式
数据编号
D1900
DataSeed大数据库
扫码添加会员助理,备注【披露度差异】

https://cndataseed.com/
点击左下角“阅读原文”,获取更多数据
