一个千亿参数的通用大模型,和一个只有80亿参数的行业小模型,在工业场景中同场竞技——结果并非谁碾压谁,而是各自展现了截然不同的"特长"。通用模型知识广博,但在专业细节上容易"犯迷糊";行业小模型知识面窄,却在特定任务上能做到又快又准。
这场对比没有输赢,却揭示了一个关键命题:AI从实验室走向产业,真正需要的不是"更大的模型",而是"更懂行业的数据"。
6月1日,京东工业在北京正式发布中国工业领域第一个大模型生态——"百川计划",从数据、模型、应用三个维度共建上游行业生态。作为首批生态合作企业,德力西电气与京东工业联合落地了电气行业专属大模型。
这个低压电气大模型只有8B参数。京东工业相关负责人介绍:"这个模型尺寸非常小,资源占用和成本都更低,运行效率也很出色。更重要的是,它在专业任务上表现得相当精准。"评测数据显示,双方依靠共建高质量数据集训练的小尺寸轻量化模型,将特定任务下的精度和准确度从80%提升至95%-97%。在导购场景中,陌生商品用户选型决策时长缩短约70%。
德力西电气首席信息官李扬坦言,此前尝试通用大模型时,确实遇到了幻觉、行业知识不足和部署不够敏捷等现实困难,"在工业场景中出现了很多不适应"。于是他们选择了另一条路径:不盲目追求参数规模,而是把重心放在行业数据的深度打磨上。
这个案例恰好印证了当前AI产业一个正在发生的趋势——从"拼模型"到"拼数据体系"的范式转移。

01

产业场景带来的三重考验
模型在产业场景中表现出现偏差,往往与以下三个方面的因素有关。

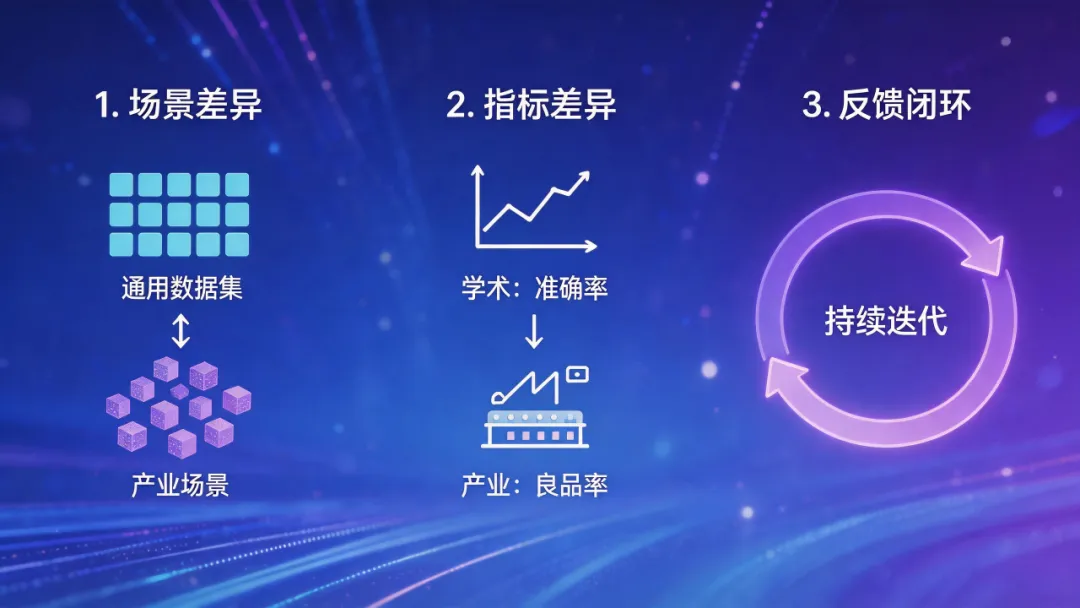
第一,场景分布的差异。
公开数据集大多来自互联网语料、标准图像库、实验室环境,而真实产业场景包含特有的噪音、边缘案例、长尾分布。一个在通用图像识别基准上准确率较高的模型,到了工业质检产线,在识别产品表面细微划痕时的效果仍有进一步优化的空间——因为训练数据中这类“缺陷样本”的覆盖可能需要加强。
第二,评价指标的差异。
学术评测关注准确率、召回率等通用指标,而产业关心的是“过检率降低了多少”“停机时间缩短了几小时”“良品率提升了几个百分点”。两者之间需要建立有效的转换关系。
第三,反馈机制的建立。
学术研究通常在模型训练完成后即告一段落;而产业中模型需要持续运行,环境、产品、用户行为都可能随时间发生变化。建立闭环反馈机制,有助于模型表现更好地跟随实际需求演进。
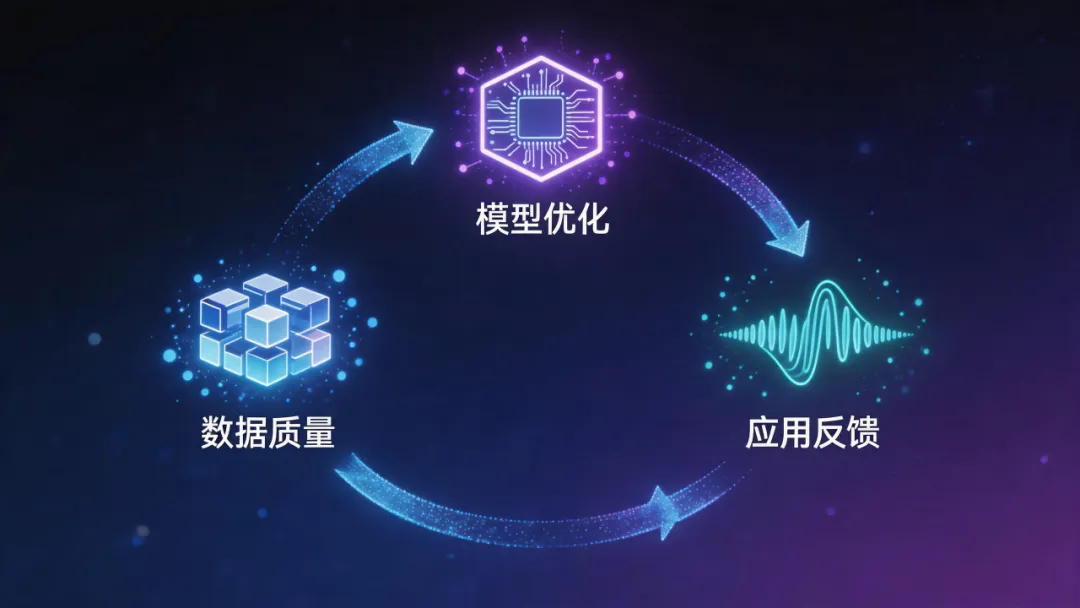
模数共振体系的核心任务之一,正是试图缓解这三方面的差异。

TalkingData洞察
在某些动态变化的业务场景中,用历史数据训练的模型在常规时期表现稳定,但遇到突发事件或新模式时,预测结果可能出现一定偏差。原因之一是训练数据中对此类场景的覆盖相对有限。解决这一问题的方式包括场景模拟和合成数据等主动补充手段。

02

"模数共振"到底是什么?
2026年4月28日,第九届数字中国建设峰会期间,工业和信息化部与国家数据局联合印发《关于联合实施2026年"模数共振"行动的通知》,正式启动"模数共振"行动。面向制造业领域20个重点行业,探索场景、模型、智能体、数据集等关键技术成果的产出路径。
同期,中国信通院联合中车工业研究院正式发布《人工智能模数共振体系研究报告(2026年)》,首次系统阐述了"模数共振"的定义、内涵与核心要素。
"模数共振"到底在"共振"什么?
"模"是模型——行业大模型、专属AI智能体;
"数"是数据——各行各业的生产数据、业务数据、工艺数据。
目标很直接:建立数据质量提升、模型优化与应用反馈的协同联动及闭环迭代机制。核心是实现 "数据动态适配模型需求、模型输出反哺数据质量提升" 的良性循环。用大白话说,就是数据越用越多,模型越练越强,应用越跑越顺——三者互相"喂饭",共同成长。
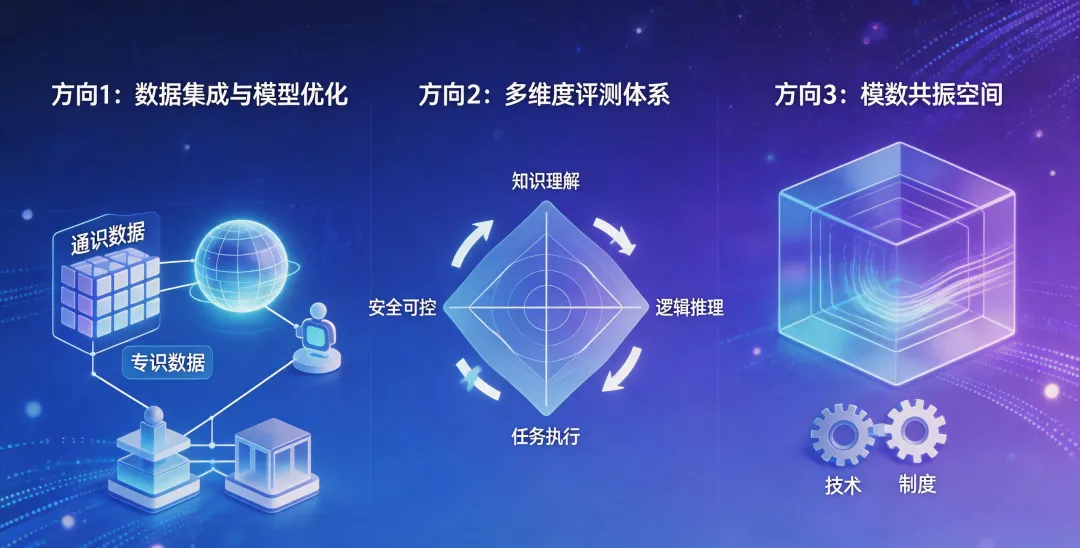
报告给出了一个产业落地框架,可以概括为“三层两环”。
三层架构
第一层——行业通识数据集 + 行业大模型:面向制造、金融、医疗、交通等重点行业,整合公域与私域数据,建设覆盖行业核心知识的通识数据集,训练具备广泛行业理解能力的行业大模型,形成通用智能底座。
第二层——专识数据集 + 特色智能体:聚焦特定细分场景,构建高知识密度、高标注精度的专识数据集,研发面向垂直场景的特色智能体,实现从通用能力到专业技能的适配。
第三层——高价值应用场景:锚定产业刚需,将行业大模型与特色智能体部署于研发、生产、管理、服务等具体业务环节,形成可量化价值的落地应用。应用场景的反馈数据可反向驱动数据集的持续优化与模型的迭代升级。
这三层并非割裂,而是通过数据闭环逐层支撑、反向传导:第一层为第二层提供基础能力,第二层为第三层提供专业服务,第三层的应用反馈则反哺第一层和第二层的数据与模型迭代。
两个闭环
评测闭环:报告强调将模型评测反馈作为数据集优化的重要依据,构建“评测诊断—数据集定向优化—模型能力提升”的循环。
生态闭环:报告提出探索建立“模数共振空间”,由第三方中立机构或央企子公司作为运营主体,打造跨主体数据汇聚与模型协同的平台,配以收益分配、责任划分等制度设计。
这套“三层两环”框架,为AI产业落地提供了一个兼具技术深度与组织保障的系统方案。


TalkingData洞察
一些成功的AI落地项目往往不是从零训练一个大模型,而是采用“行业大模型+场景微调”的组合。例如在金融风控领域,通用大模型可以处理信贷政策理解等任务,而特色智能体基于机构特有的交易数据、行为特征进行精细化判断。两者之间的数据闭环,正是模数共振体系的核心机制之一。

03

政策密集落地:
从"模数共振"到"高质量数据集"
6月是AI产业政策的"密集落地期"。
6月3日,国家数据局正式印发《关于推进行业高质量数据集建设行动的实施方案》。这是国家层面首次系统部署行业高质量数据集建设,围绕供给、流通、应用等关键环节,部署强基扩容、标注攻坚、提质增效、应用赋能、管理服务、价值释放六大专项行动。方案明确提出形成"场景牵引数据、数据驱动模型、模型赋能应用、应用创造价值"的"数据飞轮"。
6月10日,工信部印发《"人工智能+信息通信"创新发展实施意见(2026—2028年)》,围绕推动信息通信行业智能化升级、夯实AI发展底座等四个方面部署17项具体任务。
6月14日,国家数据局发布专家解读文章,进一步阐释高质量数据集建设的落地路径。
一周之内,国家数据局和工信部密集出手。一个管"数据怎么来",一个管"算力怎么通"。 信号非常清晰:AI基础设施建设,正在从"单点突破"走向"系统推进"。
与此同时,地方已经开始行动。6月7日,山西省工信厅、省数据局发布通知,在全省开展"模数共振"行动,面向钢铁、煤炭、汽车、航空航天等多个行业,明确数据集建设、智能场景落地、评测体系搭建等五大重点任务。河北也宣布将选择3个城市创建"模数共振"重点城市。长沙举办专题数据大讲堂,推进高质量数据集建设和模数共振落地。
政策不只是在纸面上,已经铺到了产业的第一线。


04

"模数共振"在产业里已经跑出结果了
除了德力西电气,更多数据正在验证这套逻辑的可行性:

区域层面:有城市建成超过140个行业数据集,累计支撑100个人工智能模型及智能体训练开发,实现降本约4亿元,带动新增营收及相关投资合计约7亿元。有省份在医疗、交通、工业、能源等领域形成高质量数据集521个,总规模超95PB。
智能驾驶领域:有企业利用高质量数据集填补了中国复杂交通场景的数据空白,为高级别自动驾驶研发提供了新的数据来源。
工业制造领域:有企业通过数百万张级别的专业图片数据集和上百种缺陷检测模型,将缺陷过检率降低了90%。
这些案例的共同特征是:锚定具体场景,以数据驱动模型,以模型反哺业务——与报告定义的"高价值应用"三特征高度吻合。


TalkingData洞察
高质量数据集不仅是成本中心,更可以成为价值创造中心。数据集的价值,最终需要通过应用场景来兑现。从德力西电气到城市级降本增效数据,数据与模型的闭环迭代正在多个行业被验证。这一模式对于拥有规模化数据资产和模型应用场景的企业具有普遍参考价值。
下一步:从"盆景"到"风景"
报告和公开政策已经为模数共振划定了几个值得关注的方向:
一是"通识+专识"双轨并行。 分行业整合数据,构建"通识数据集+专识数据集",相应培育"行业大模型+特色智能体",实现分层精准赋能。
二是评测从"打分"走向"诊断"。 建立覆盖多维度、分行业的评测标准与数据集,强化评测结果对数据集优化的指导,形成"评测—优化—提升"闭环。
三是"模数共振空间"值得关注。 行动通知提出,选择第三方中立机构或龙头企业作为建设运营主体,打造"模数共振"空间,研发能够承载跨主体数据汇聚和模型训练的软硬件基础设施。鼓励"模数共振"空间与国家数据基础设施互联互通,实现多主体数据高效可信流通,逐步打造为 "智能体工厂" 。
德力西电气那个8B参数小模型的故事,揭示了一个朴素但容易被忽略的道理:在产业场景中,"懂行"比"聪明"更关键。而"懂行"的前提,是有足够多、足够好的行业数据。
模数共振体系的价值,不在于发明了什么新技术,而在于它把数据、模型、场景三个要素重新组织成了一个闭环系统——让模型在真实场景中持续学习,让数据在应用反馈中持续优化。
中国信通院报告指出,模数共振体系是推动人工智能与实体经济深度融合发展的系统性工程。从6月密集落地的政策来看,这场变革已经从顶层设计走向了产业一线。
AI产业化的下一程,比的不是谁的参数更大,而是谁能在真实场景中跑通"数据-模型-应用"的持续迭代循环。
从"盆景"到"风景",模数共振正在为AI赋能实体经济铺一条路。这条路能走多远,取决于有多少企业愿意把数据从"成本中心"变成"价值中心"。
您的行业,是否正在探索AI落地的“最后一公里”?
欢迎评论区聊聊。
免责声明:
本文基于中国信通院《人工智能模数共振体系研究报告(2026年)》;工信部、国家数据局《关于联合实施2026年"模数共振"行动的通知》;国家数据局《关于推进行业高质量数据集建设行动的实施方案》;工信部《"人工智能+信息通信"创新发展实施意见(2026—2028年)》;经济日报等媒体报道撰写,引用内容已标明出处。文中所有分析、观点及解读均为基于公开信息的独立判断,不代表报告编制单位或任何其他机构的立场。文章内容仅供参考,不构成任何投资或决策建议。

END

关注TalkingData,获取更多数据洞察与行业分析。




高质量数据集是未来AI 发展的支撐。

为人工智能提供所需的一切数据
Delivering Comprehensive AI Data for All Industries.
#Data AI# #万亿数据要素市场#
推荐阅读:

国家数据局这份新方案,给AI数据定了新方向:多模态·多领域·多形态

从开环到闭环:模数共振如何让AI模型“越用越聪明”?

国家划重点:20行业AI落地,数据先“筑基”|2026模数共振行动解读


TalkingData
用数据优化决策、加速转型
欢迎关注分享