作者 | 乔钰杰
编辑| 袁斯来
硬氪获悉,隼瞻科技有限公司(下称“隼瞻科技”)近日完成近亿元天使+轮融资。本轮融资引入英飞尼迪资本、白云金控、深圳中小担创投、厚天资本、华盖资本、嘉誉创投等多家战略投资人,老股东毅达资本、达泰资本持续加持。
隼瞻科技成立于2023年初,专注芯片处理器模块及开发平台,致力于打造基于“RISC-V+DSA”的新一代处理器设计体系,公司希望通过“IP货架+EDA工具链”的模式,降低AI时代定制化处理器设计门槛。
当前,AI模型快速垂直化,正在推动芯片产业从“通用计算”走向“专用计算”。
过去,以CPU为核心的架构长期主导芯片设计,但AI算法以大规模二维、三维矩阵运算为主,在传统CPU上的运行效率并不理想。行业也逐渐转向NPU、VPU、TPU等专用处理器协同的异构计算体系。
与此同时,AI模型的快速垂直化,也让芯片设计开始从“通用适配”走向“模型驱动”。
“过去很多算法都能直接跑在CPU上,但AI时代以后,不同场景、不同模型之间差异巨大。”隼瞻科技创始人曾轶表示,“客户越来越希望芯片能围绕自己的模型进行定制,从而在功耗、面积和成本之间找到最佳平衡。”
这也是DSA(领域专用架构)兴起的重要背景。
DSA本质上是“让架构为模型服务”。相比传统通用处理器追求“大而全”,DSA更强调围绕具体算法和场景进行资源配置。例如,在AI推理场景中,客户可根据模型特点,自定义CPU、DSP、NPU等模块的算力占比,避免资源冗余。
而RISC-V,则被认为是DSA的重要底座。
曾轶介绍称,相较ARM等传统闭源架构,RISC-V具备开源、可扩展、可定制等天然优势,尤其适合AI时代快速变化的模型需求。
更重要的是,RISC-V能够为未来模型演进预留可编程空间。“AI模型变化非常快,如果底层架构无法灵活扩展,芯片生命周期会被迅速压缩。”曾轶表示。因此,隼瞻在架构设计中,会提前预留二维指令、函数空间以及后续可编程能力,以适应未来模型升级。
不过,DSA真正落地的核心难点,并不只是理念,而是工程化能力。
传统情况下,一个中等规模DSA处理器的开发,往往需要数十位工程师、耗时半年以上,且涉及复杂的软件工具链协同。尤其在多核异构环境下,不同处理器对应不同编译器与开发环境,工程复杂度极高。
因此,隼瞻科技从成立之初,就同步布局IP与EDA平台。
目前,公司已经形成完整RISC-V产品矩阵,包括CPU IP、DSP IP以及NPU IP。其中,其中多款处理器IP已经实现量产。
与此同时,隼瞻自研的高度智能化的专用处理器设计平台ArchitStudio,可覆盖架构分析、处理器设计、RTL生成以及软件工具链自动生成等完整流程。
该平台由多个核心引擎构成,覆盖架构分析、设计优化到自动生成的完整流程。例如,Archit Analyzer可分析客户算法在现有处理器上的运行瓶颈,并自动识别计算效率低下的算子;Archit Designer则允许开发者通过高层语言直接描述架构需求,无需手写底层RTL代码;最终,Archit Generator还能自动生成RTL、验证环境及完整软件工具链。
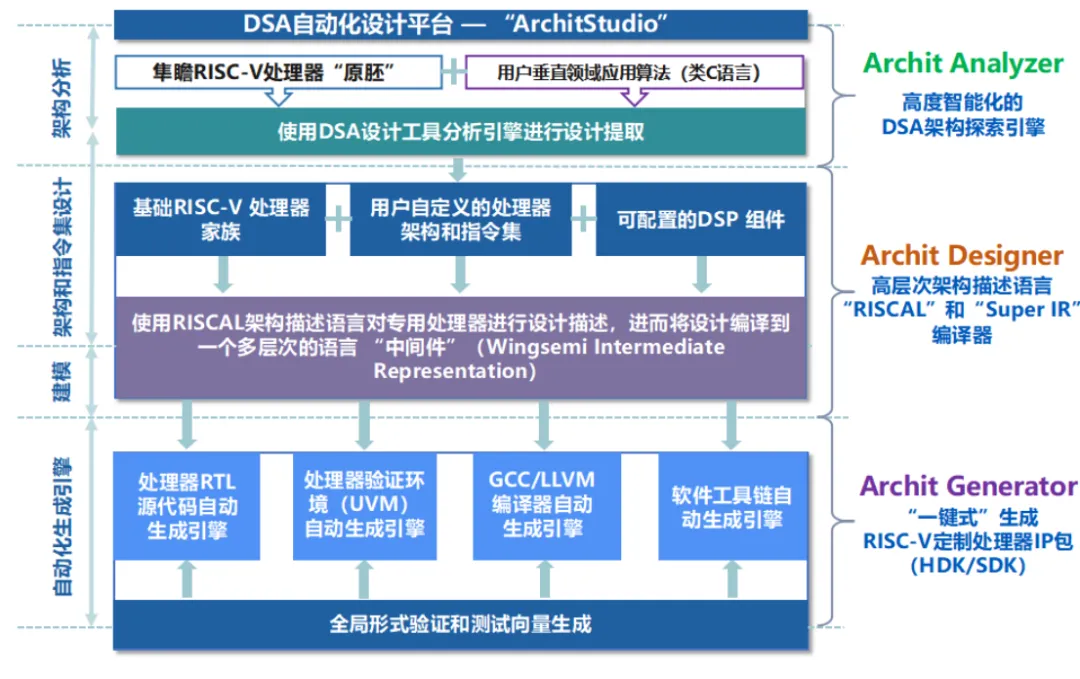
ArchitStudio示意图(图源/企业)
目前,公司已在无线通信、多媒体处理、信息安全、工业控制、汽车电子与AI端侧等领域实现客户落地。
例如,在无线通信领域,公司为客户定制通信DSP;在信息安全领域,其帮助头部安全芯片厂商将核心安全算法融入DSA架构;在机器人方向,则已应用于机器人电机与灵巧手控制系统。
商业模式方面,隼瞻目前主要包括三类:标准化IP授权、整体DSA方案销售,以及更高层级的多核异构平台定制服务。
团队方面,隼瞻科技核心团队来自于Synopsys、ARM等国内外顶尖半导体设计公司,全栈覆盖研发、销售、技术支持等领域,团队在RISC-V、处理器架构和EDA方向具备长期的深厚积累。
以下为硬氪与隼瞻科技创始人曾轶访谈节选(略经编辑):
硬氪:为什么AI时代会推动DSA(领域专用架构)成为趋势?
曾轶:过去很多算法都能直接运行在CPU上,但AI时代以后,模型开始高度垂直化。不同场景、不同客户之间,模型结构差异非常大。如果继续使用传统通用架构,就会出现大量资源浪费。比如有些客户真正需要的是NPU算力,有些则更依赖DSP或者特定数据通路,但传统SoC往往是“大而全”的设计方式。
DSA本质上是“让架构为模型服务”。客户可以围绕自己的模型特点,决定CPU、DSP、NPU等模块的资源占比,从而在性能、功耗、面积和成本之间实现最优平衡。这也是为什么我们认为,AI时代的芯片设计,会逐渐从“通用芯片”转向“定制化架构”。
硬氪:隼瞻为什么选择“RISC-V+DSA”这一路线?
曾轶:DSA天然需要一个高度开放、可扩展、可定制的底层架构,而RISC-V正好具备这些特点。相比传统闭源架构,RISC-V最大的优势在于指令集可扩展。客户可以根据自身模型需求,对处理器进行深度定制,包括专用指令、数据通路甚至调度方式。
尤其在AI场景里,很多性能瓶颈其实不在算力本身,而在数据搬运和调度效率。如果通过定制RISC-V指令集对NPU进行协同调度,效率提升可能是数十倍甚至百倍级别。
更重要的是,AI模型变化非常快。我们在设计时,也会提前预留后续可编程空间,让芯片能够适应未来模型迭代,而不是几年后就被淘汰。
硬氪:隼瞻的核心壁垒是什么?
曾轶:很多公司是先做IP,再逐步补工具链,但这样往往会出现兼容性和协同效率问题。
我们从创业第一天开始,就是把IP和EDA平台一起规划的。所有CPU、DSP、NPU内核,都是基于自研工具开发出来的,因此工具链和架构之间能够实现深度协同。
此外,我们不仅仅提供标准IP,而是希望把DSA能力平台化。传统情况下,一个中等规模DSA处理器设计,可能需要30个人做30周。我们希望通过ArchitStudio,把它压缩到3个人、3周左右。本质上,我们是在降低定制化处理器设计门槛,让更多芯片公司具备过去只有大厂才拥有的能力。