

"停机!快停机!"
凌晨三点,某电子元器件厂的车间里,一阵急促的喊声打破了夜的宁静。生产主管老张满头大汗地冲到生产线前,看着传送带上源源不断流过的产品,脸色铁青。
就在半小时前,客户打来电话:上一批货有大量不良品,要求全部退货。初步排查,是昨晚生产的那批产品出了问题。可具体是哪个环节出了问题?什么时候开始出问题的?有多少产品受影响?——这些问题,没人能回答。
"要是能早点发现就好了……"老张叹了口气,心里五味杂陈。这不是第一次了,也不会是最后一次。
在高速生产线上,质量问题就像幽灵一样,悄无声息地出现,等你发现时,往往已经造成了巨大的损失。传统的质检方式,在高速、高精度的生产场景下,越来越力不从心。
这篇文章,聊聊高速生产线的质量控制策略——如何在生产过程中实时发现问题、如何在问题扩大前及时止损、如何让质量控制从"事后补救"变成"实时预防"。
第一部分:技术演进——AI视觉检测如何改变质检格局
1.1 从"人眼时代"到"智能时代"
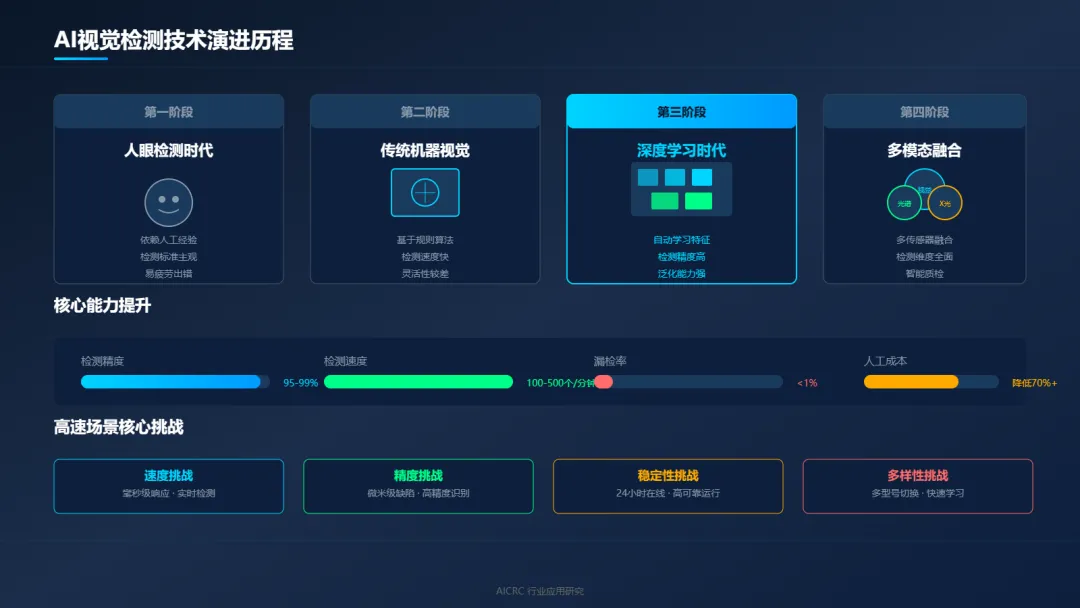
回望工业质检的发展历程,就像一部从"人"到"机器"再到"智能"的进化史。
第一阶段:人眼检测时代
那是质检的"原始社会"。产品从生产线上下来,一排排质检员坐在传送带旁边,眼睛盯着产品,一个一个地看、一个一个地挑。检测标准全靠经验,检测结果因人而异,数据记录靠手写,追溯起来比登天还难。
"以前我们车间有三十多个质检员,三班倒,眼睛都看花了。"一位老质检员回忆道,"有时候盯久了,眼睛发花,明明是好的产品也看成坏的,明明有缺陷的产品却漏过去了。"
第二阶段:传统机器视觉时代
工业相机出现了,机器开始"看"产品。工程师们编写规则,告诉机器什么是"好"、什么是"坏"。检测速度上去了,一致性也好了,但问题来了——规则是死的,产品是活的。
一旦产品换了型号、缺陷换了样子,工程师就得重新写规则、调参数。遇到复杂的缺陷,传统方法往往束手无策。
第三阶段:深度学习时代
神经网络让机器学会了"自己看"。不需要人工设计特征,只要给模型足够多的样本,它就能自动学会识别各种缺陷。检测精度大幅提升,泛化能力显著增强,适应性越来越好。
第四阶段:多模态融合时代
单一视觉检测已经不够了。视觉、光谱、X光、热成像……多种检测手段融合,从表面到内部、从形貌到成分,全方位把控产品质量。
1.2 高速场景下的独特挑战
高速生产线,是质检技术的"终极考场"。
速度的挑战:每分钟数百个产品从传送带上飞驰而过,检测系统必须在毫秒级时间内完成图像采集、处理、判断、反馈。稍有延迟,不良品就已经混入良品堆里了。
精度的挑战:高速运动带来的运动模糊、光照变化、产品位置偏移,都给检测精度带来巨大压力。一个微小的划痕、一个肉眼难辨的色差,都可能成为致命缺陷。
稳定性的挑战:生产线24小时不停机,检测系统也必须24小时在线。任何一次故障、任何一次误判,都可能造成批量质量问题。
多样性的挑战:产品型号多、缺陷类型杂,检测系统必须具备强大的适应能力,能够快速切换、快速学习。
第二部分:算法解析——传统方法与深度学习的较量
2.1 传统机器视觉:老牌选手的实力与局限

传统机器视觉就像一位经验丰富的老师傅,有一套固定的"看家本领"。
边缘检测:用Canny、Sobel等算子,找出图像中的边缘和轮廓。适合检测裂纹、划痕等边界清晰的缺陷。
阈值分割:根据灰度值把图像分成不同区域。适合检测颜色差异明显的缺陷,如污渍、色差等。
模板匹配:拿一张"标准图"和待检测图像比对,找出不一样的地方。适合产品固定、缺陷规律的场景。
形态学处理:用腐蚀、膨胀等操作,去除噪声、填充空洞。常作为预处理或后处理步骤。
传统方法的优势:
计算速度快,对硬件要求低,在简单的检测场景下表现稳定。更重要的是,算法原理清晰,可解释性强——出了问题,知道是哪里出了问题。
传统方法的局限:
需要大量人工调参,对复杂缺陷识别能力有限,泛化能力弱。一旦产品变了、缺陷变了,就得重新调整。在高速、高精度的复杂场景下,传统方法往往力不从心。
2.2 深度学习:新锐选手的崛起
深度学习就像一个天赋异禀的学徒,不需要你告诉它怎么看,只要给它足够多的样本,它就能自己学会。
卷积神经网络(CNN):图像识别的基石。通过卷积层自动提取图像特征,从低级的边缘纹理到高级的语义信息,层层递进。
ResNet:深层网络的破局者。用残差连接解决了深层网络的退化问题,让网络可以做得更深、更强。
YOLO系列:实时检测的王者。单阶段检测架构,速度快、精度高,特别适合高速生产线上的实时检测场景。
U-Net:像素级分割的利器。能够精确地勾勒出缺陷的轮廓和边界,适合需要精确测量的检测任务。
Vision Transformer:注意力机制的引入。用自注意力机制建模图像的全局上下文,在某些场景下超越了传统CNN。
深度学习的优势:
自动学习特征,无需人工设计;对复杂缺陷识别能力强;泛化能力好,适应性强;检测精度高,可达99%以上。
深度学习的挑战:
需要大量标注数据;训练成本高,算力需求大;模型是"黑盒",可解释性差;对数据质量要求高。
2.3 如何选择:场景决定方法
数据量小(<1000张):传统方法为主,深度学习为辅
数据量中等(1000-10000张):轻量级深度学习模型(MobileNet、EfficientNet)
数据量大(>10000张):深度模型(ResNet、YOLO、Transformer)
实时性要求极高:YOLO系列、轻量级模型
精度要求极高:两阶段检测模型、集成学习
需要可解释性:传统方法+深度学习混合
第三部分:数据集构建——从数据采集到质量标注
3.1 数据采集:好数据是好模型的基础
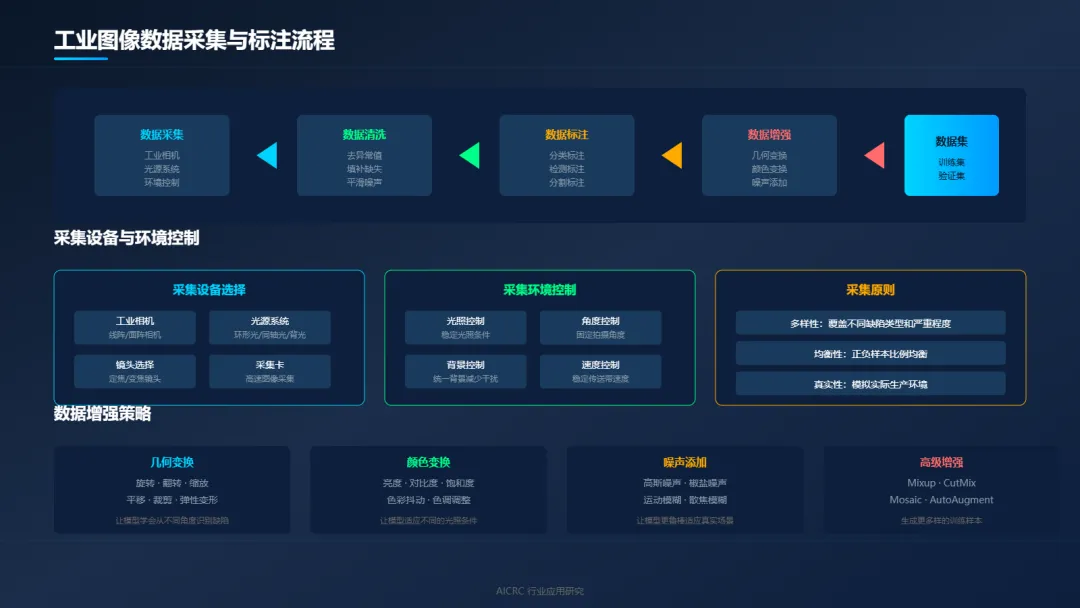
"垃圾进,垃圾出。"这是机器学习领域的铁律。再好的算法,如果用垃圾数据训练,也只能得到垃圾模型。
采集设备的选择:
工业相机是数据采集的核心。线阵相机适合连续运动的带状产品,面阵相机适合离散的单件产品。分辨率要足够高,帧率要足够快,才能在高速生产线上捕捉清晰的图像。
光源系统同样关键。环形光、同轴光、背光……不同的光源配置,能突出不同类型的缺陷。好的光照设计,能让缺陷"显形",让检测事半功倍。
采集环境的控制:
光照要稳定,避免外界光线的干扰;角度要固定,减少产品位置变化带来的影响;背景要统一,降低噪声干扰;速度要匹配,避免运动模糊。
采集策略的设计:
要覆盖各种缺陷类型、各种严重程度、各种工况条件。正负样本要均衡,不能全是缺陷样本,也不能全是正常样本。要采集真实场景数据,不要只在实验室里"摆拍"。
3.2 数据标注:人工智慧的最后一公里
标注是数据集构建中最耗时、最枯燥、也最关键的环节。
标注类型的选择:
分类标注:这张图有没有缺陷?最简单,但信息量最少。
检测标注:缺陷在哪里?是什么类型?用矩形框标注。
分割标注:缺陷的精确轮廓是什么?像素级标注,精度最高但工作量最大。
标注质量的控制:
制定统一的标注规范,让所有标注人员按照相同的标准操作;对标注人员进行培训,确保他们理解标注要求;多人标注、交叉验证,发现并纠正标注错误;定期抽检,把控整体标注质量。
3.3 数据增强:让有限的数据发挥最大价值
工业场景下,缺陷样本往往稀缺。数据增强,是解决数据不足的有效手段。
几何变换:旋转、翻转、缩放、平移、裁剪。让模型学会从不同角度识别缺陷。
颜色变换:亮度、对比度、饱和度调整。让模型适应不同的光照条件。
噪声添加:高斯噪声、椒盐噪声、运动模糊。让模型更鲁棒,更能适应真实场景。
高级增强:Mixup、CutMix、Mosaic。通过图像混合和拼接,生成更多样的训练样本。
增强的原则:保持缺陷特征不变,模拟真实场景变化,避免过度增强导致失真。
第四部分:模型训练与优化——从架构选择到性能调优
4.1 网络架构选择:适合的才是最好的
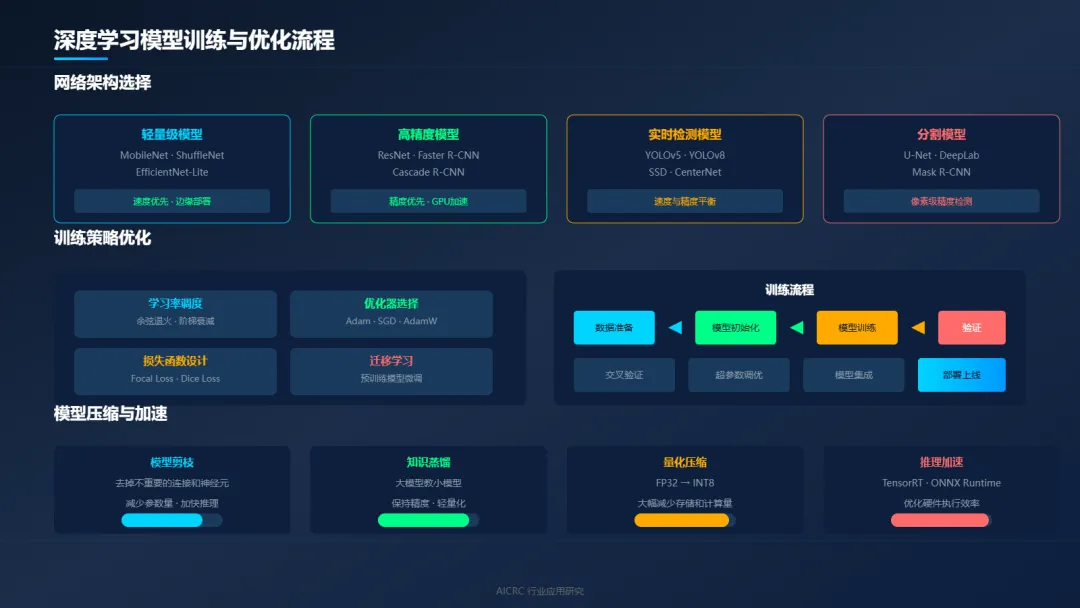
轻量级模型:速度优先
MobileNet、ShuffleNet、EfficientNet-Lite……这些模型参数少、计算量小,特别适合部署在边缘设备上。在高速生产线上,检测速度往往比检测精度更重要——宁可偶尔漏掉一个微小缺陷,也不能让生产线停下来等待检测结果。
高精度模型:精度优先
ResNet、Faster R-CNN、Cascade R-CNN……这些模型精度高、能力强,适合对精度要求极高的检测场景。代价是计算量大、速度慢,通常需要GPU加速。
实时检测模型:速度与精度的平衡
YOLO系列是实时检测的代表。从YOLOv5到YOLOv8,速度越来越快、精度越来越高。在高速生产线上,YOLO系列几乎是标配。
分割模型:像素级精度
U-Net、DeepLab、Mask R-CNN……当需要精确测量缺陷面积、勾勒缺陷轮廓时,分割模型是最佳选择。
4.2 训练策略优化:让模型学得更好
学习率调度:从大的学习率开始,逐步减小。让模型先快速收敛,再精细调整。
优化器选择:Adam收敛快,SGD泛化好。根据实际情况选择,或者用Adam预热再切换到SGD。
损失函数设计:交叉熵损失适合分类,Focal Loss解决类别不平衡,Dice Loss适合分割任务。
数据增强策略:在线增强在训练时实时进行,离线增强预先生成增强样本。两者结合效果更好。
迁移学习:用预训练模型初始化,再在自己的数据上微调。可以大大减少训练时间和数据需求。
4.3 模型压缩与加速:让模型跑得更快
训练好的模型,往往太大、太慢,无法满足高速生产线的实时检测需求。模型压缩与加速,是必不可少的环节。
模型剪枝:去掉模型中不重要的连接和神经元,让模型变小、变快。
知识蒸馏:用大模型教小模型,让小模型继承大模型的知识,同时保持轻量。
量化压缩:将模型参数从32位浮点数压缩到8位整数,大幅减少存储和计算量。
推理加速:用TensorRT、ONNX Runtime等推理引擎,优化模型在特定硬件上的执行效率。
第五部分:系统架构——边缘计算与云端协同
5.1 边云协同架构设计
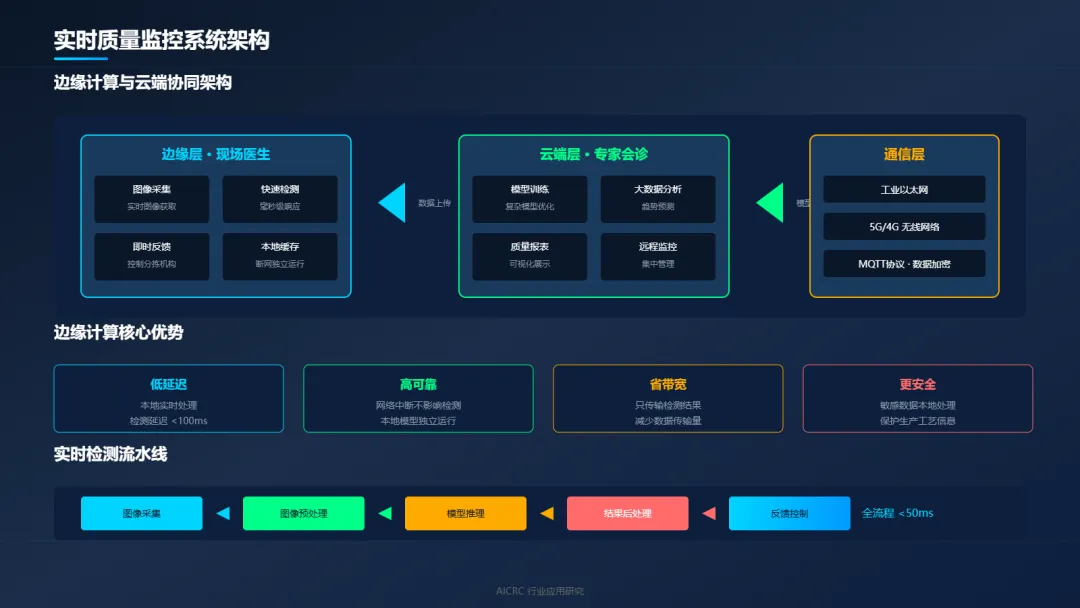
高速生产线的质量检测,对实时性要求极高。传统的"采集-传输-处理-反馈"模式,延迟太高,无法满足需求。边缘计算,应运而生。
边缘层:现场医生
部署在生产线旁的边缘设备,负责实时图像采集、快速缺陷检测、即时反馈控制。
边缘层的优势:
低延迟:毫秒级响应,满足高速检测需求
高可靠:网络中断时仍可独立运行
省带宽:只上传检测结果,不上传原始图像
更安全:敏感数据不出厂区,保护生产工艺
云端层:专家会诊
云端服务器负责复杂模型训练、大数据分析、质量报表生成、远程监控诊断。
云端层的优势:
强算力:支持大规模模型训练
大存储:保存历史数据,支持追溯分析
易扩展:按需分配资源,灵活调整
便管理:统一监控多条产线,集中维护
5.2 实时检测流水线设计
在高速生产线上,检测系统必须像流水线一样高效运转。
图像采集:工业相机以固定帧率采集图像,存入缓冲区。
图像预处理:去噪、增强、归一化,为检测做好准备。
模型推理:用训练好的模型进行缺陷检测,输出检测结果。
结果后处理:过滤误检、合并重叠检测框、输出最终结果。
反馈控制:根据检测结果,控制分拣机构剔除不良品。
整个流程要在几十毫秒内完成,任何一个环节的延迟都会影响整体性能。
第六部分:多模态融合——超越视觉的综合检测
6.1 为什么需要多模态检测?

单一视觉检测,就像只用眼睛看世界——能看到表面,却看不到内部;能看到形貌,却看不到成分。
在高端制造领域,很多缺陷是"隐形"的:内部的气泡、夹杂物,材料的成分偏差,涂层的厚度不均……这些缺陷,肉眼看不见,相机拍不到,但会影响产品的性能和寿命。
多模态检测,就是给质检系统装上"透视眼"和"化学分析仪"。
6.2 多模态检测技术全景
视觉检测:表面缺陷、尺寸测量、颜色识别、形状分析。最基础、最常用的检测手段。
光谱检测:近红外、拉曼、荧光光谱。能检测材料的成分、含水率、内部结构。适合食品、药品、化工等行业。
X光检测:内部缺陷、密度分析、结构完整性。能"看穿"产品内部,发现隐藏的缺陷。适合电子元器件、铸件、焊接件等。
超声波检测:厚度测量、内部缺陷、粘接质量。非破坏性检测,适合复合材料、焊接结构等。
热成像检测:温度分布、热缺陷、设备状态。能发现过热、短路等问题,适合电子产品、电池等。
6.3 数据融合策略
早期融合(特征层融合):在特征提取阶段就融合多模态数据。保留最完整的信息,但计算复杂度高。
中期融合(决策层融合):各模态独立检测,在决策阶段融合结果。计算效率高,灵活性强。
后期融合(结果层融合):各模态独立输出结果,通过规则或模型进行最终判断。实现简单,可解释性强。
融合的关键是找到各模态之间的关联和互补性,让"1+1>2"。
第七部分:对比分析——AI质检与传统方法的较量
7.1 准确性对比
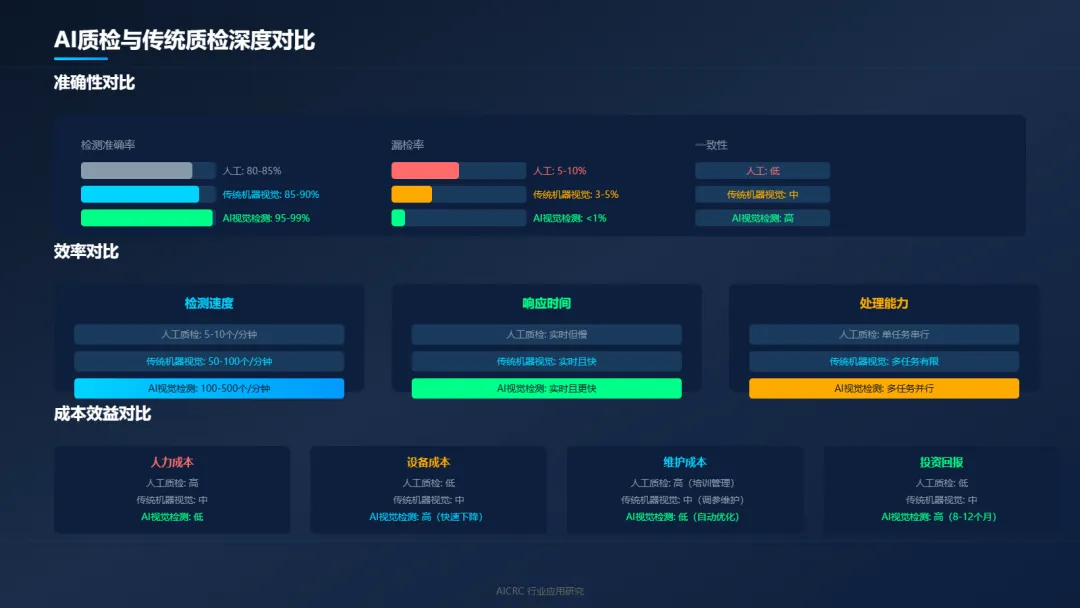
检测准确率是质检系统的生命线。
人工质检:准确率80-85%,受人员状态、疲劳程度、经验水平影响大。漏检率5-10%,误检率10-15%。
传统机器视觉:准确率85-90%,对简单缺陷检测效果好,对复杂缺陷识别能力有限。漏检率3-5%,误检率5-10%。
AI视觉检测:准确率95-99%,对复杂缺陷识别能力强,泛化能力好。漏检率<1%,误检率<2%。
在高速生产线上,AI视觉检测的优势更加明显。人工质检跟不上生产速度,传统机器视觉适应不了复杂缺陷,只有AI视觉检测能够兼顾速度和精度。
7.2 效率对比
检测速度:
人工质检:5-10个/分钟
传统机器视觉:50-100个/分钟
AI视觉检测:100-500个/分钟
响应时间:
人工质检:实时但慢
传统机器视觉:实时且快
AI视觉检测:实时且更快
处理能力:
人工质检:单任务串行
传统机器视觉:多任务有限
AI视觉检测:多任务并行
7.3 成本效益对比
人力成本:人工质检最高,需要大量质检员三班倒;AI视觉检测最低,自动化程度高。
设备成本:人工质检最低;AI视觉检测较高,但正在快速下降。
维护成本:人工质检最高,需要持续培训和管理;AI视觉检测较低,模型可以自动优化。
投资回报:AI视觉检测ROI通常在8-12个月,之后就是纯收益。
第八部分:生产线集成——与MES、ERP系统对接实现闭环控制
8.1 系统集成的价值
质检系统不是孤岛,必须与生产管理系统深度集成,才能发挥最大价值。
与MES系统集成:
实时上传质检数据,关联生产批次和设备信息;根据质检结果调整生产参数,实现闭环控制;生成质量报表,支持追溯分析。
与ERP系统集成:
质量数据归档,支持长期追溯;质量成本核算,量化质量损失;供应商质量评估,优化供应链管理。
8.2 闭环控制的实现
检测→分析→改进→再检测
实时检测缺陷,记录缺陷类型和位置
分析缺陷原因,追溯生产过程数据
制定改进措施,调整生产参数
验证改进效果,持续优化提升
闭环控制让质量问题不再是"事后补救",而是"实时预防"。
第九部分:高精密高速场景的挑战与解决方案
9.1 高精密场景:微米级的较量
挑战:缺陷尺寸微小,检测精度要求极高,环境干扰因素多。
解决方案:
高分辨率成像系统,捕捉微小细节
多尺度检测策略,兼顾大缺陷和小缺陷
环境控制与补偿,减少外界干扰
主动学习标注,持续优化模型
9.2 高速场景:毫秒级的竞速
挑战:检测速度要求高,实时性要求强,数据处理量大。
解决方案:
轻量级模型设计,降低计算复杂度
边缘计算加速,减少传输延迟
流水线并行处理,提高吞吐量
冗余设计保障,确保系统稳定
9.3 复杂场景:多样性的考验
挑战:缺陷类型多样,产品种类繁多,样本不平衡严重。
解决方案:
多任务学习模型,一次训练多种缺陷
迁移学习技术,快速适应新产品
数据增强策略,解决样本不平衡
持续学习机制,不断学习新缺陷
第十部分:校准、验证与性能评估
10.1 系统校准

硬件校准:相机标定、光源校准、传送带速度校准、传感器校准。
软件校准:模型参数调优、阈值设置、检测区域设置、置信度调整。
定期校准:每周例行校准、每月全面校准、每季度精度验证、每年系统评估。
10.2 模型验证
验证方法:交叉验证、留出验证、实际生产验证、第三方验证。
验证指标:准确率、精确率、召回率、F1分数、检测速度(FPS)。
10.3 性能评估
评估维度:检测精度、检测速度、系统稳定性、鲁棒性、可维护性。
评估标准:行业标准、客户要求、内部标准、国际标准。
持续优化:定期评估、问题分析、改进措施、效果验证。
总结与思考
高速生产线的质量控制,是一场与时间、精度、稳定性的较量。AI视觉检测技术的出现,让这场较量有了新的武器。
实施AI视觉检测,企业可以获得:
95-99%的检测准确率
10-50倍的检测速度提升
70%以上的人工成本降低
8-12个月的投资回报周期
完整的质量追溯能力
但成功实施需要企业具备:
数据基础:高质量的缺陷样本数据
技术能力:深度学习和计算机视觉能力
硬件支持:高性能的计算和成像设备
系统集成:与生产系统的无缝对接
持续优化:模型迭代和系统优化的能力
AI视觉检测不是一蹴而就的技术,而是需要持续投入和优化的长期工程。但一旦成功,它将成为企业质量控制的强大武器,帮助企业在激烈的市场竞争中立于不败之地。
思考问题
您的生产线中哪些环节最适合应用AI视觉检测?面临哪些技术挑战?
欢迎在评论区分享您的想法和经验!

关于AICRC 行业应用研究
AICRC 行业应用研究是专为中小制造企业打造的智能化转型研究机构,通过科学的评估体系、智能的规划引擎和专业的指导服务,帮助企业制定个性化的AI转型方案,降低转型风险,提升投资回报。
