
这一篇,我们讲:
怎么把它变成系统。
不是一次分析。
是每天自动跑。
一、核心目标是什么?
很多人做 AI 电商有个误区:
每天找爆款。每天手动分析。每天手动改提示词。每天手动测试。
这叫打零工。
我们要做的是:
爆款结构数据库 + 自动拆解流水线。
目标状态是:
刷到爆款 → 三击手机 → 自动入库 → 自动分析 → 自动生成复刻包。
人只做判断。
系统负责拆解。
二、整体架构图
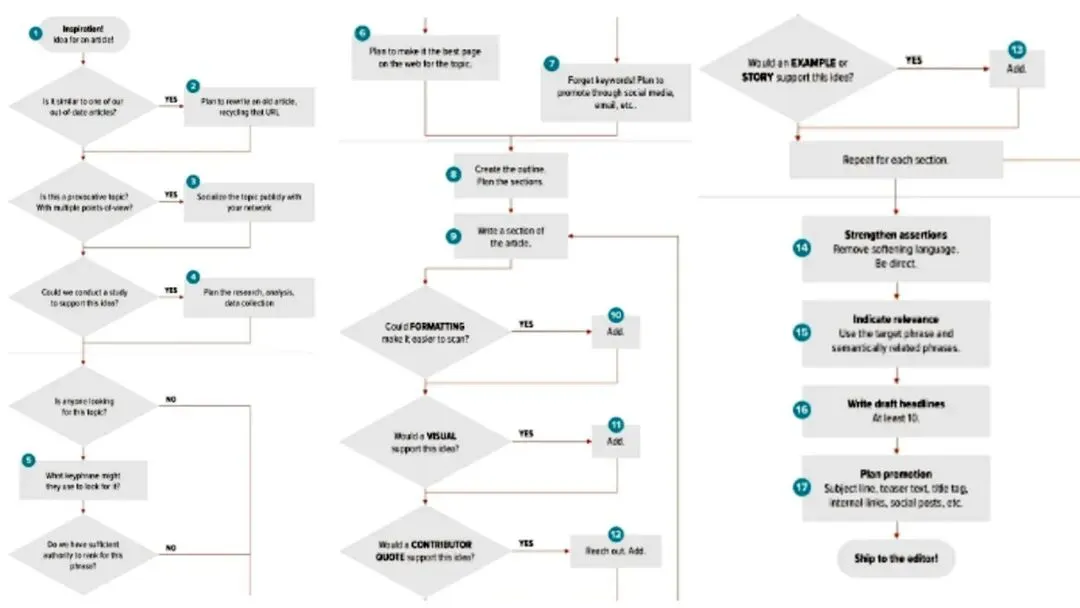
系统可以拆成 6 层:
1️⃣ 视频获取层2️⃣ 存储层3️⃣ 分析层4️⃣ 结构化层5️⃣ 生成层6️⃣ 输出层
我们逐层讲。
三、第一层:视频捕获
目标:
尽量简单。
方案有三种:
① 手动下载上传② 快捷指令 + 云端接口③ 自动爬取指定账号
推荐:
手机快捷指令 → 上传到服务器 → 返回 video URL。
做到:
3 秒完成捕获。
四、第二层:素材存储
建议:
对象存储 + 数据表。
视频文件进 OSS
元数据进多维表格
字段至少包括:
产品类目
视频链接
钩子类型
场景类型
运镜结构
语气类型
转化方式
评论亮点
销售数据
一开始字段可以简单。
后期会越来越细。
五、第三层:AI 分析层(最关键)
这里才是 Seed 2.0 出场的地方。
它要做三件事:
1️⃣ 视频结构拆解2️⃣ 爆款原因归纳3️⃣ 复刻提示词生成
流程示意:
视频 → VLM理解 → 结构拆分 → 输出 JSON
例如输出结构:
{ hook_type: "情绪惋惜促销型", camera_style: "第一人称轻微抖动", core_selling_point: "承重450磅 + 6档调节", trust_signal: "仓储环境库存感", voice_style: "假惋惜+兴奋"}
这个 JSON 才是资产。
不是那段文字分析。
六、第四层:结构化数据库
为什么要结构化?
因为长期价值在这里。
当你积累:
100 条爆款
300 条爆款
500 条爆款
你可以开始回答:
哪种钩子转化最高?
哪种场景信任度最高?
哪种情绪结构更容易成交?
不同类目适配哪种叙事节奏?
这一步,是从“模仿”到“预测”的关键。
七、第五层:自动生成复刻包
这一层开始赚钱。
根据结构化数据生成:
8 秒复刻脚本
25 宫格分镜
UGC 视频提示词
封面文案
评论区引导话术
甚至可以生成:
剪映工程参数
字幕模板
背景音乐建议
一条爆款视频 → 产出完整生产包。
这叫:
爆款工厂。
八、第六层:输出层
输出可以分三种:
① 内部用② 卖服务③ 做 API
如果你是团队操盘手:
用内部系统。
如果你做 SaaS:
卖爆款拆解订阅。
如果你做 API 聚合(比如你现在做的):
可以做:
爆款结构分析接口。
九、真正的壁垒在哪?
不是模型。
不是接口。
是数据库。
当你拥有:
1000 条爆款结构
不同类目拆解规律
情绪钩子统计数据
你已经拥有:
爆款知识图谱。
这才是护城河。
十、未来升级方向
Seed 2.0 现在只是分析。
下一步是:
Agent 自动执行。
未来可以做到:
自动找爆款自动生成复刻视频自动发布测试号自动统计数据自动优化结构
那时候,
人只负责选方向。
系统负责跑实验。
十一、一个现实判断
AI 电商会分成两类人:
第一类:每天找爆款,手动复刻。
第二类:搭系统,让 AI 复刻。
差距会越来越大。
因为第二类在积累结构资产。
第一类在重复劳动。
十二、送你一句话
模型越来越强。
真正稀缺的是:
结构化思维 + 系统能力。
谁把爆款拆成结构。
谁就能批量制造爆款。
