

在真实的 AI 应用落地过程中,能跑 Demo 的模型,并不一定能长期跑在系统里。许多视觉语言模型在评测和展示阶段表现亮眼,但一旦进入生产环境,往往会暴露出稳定性不足、资源消耗高、行为不可控等问题,难以支撑长期、高频的业务使用。
openPangu-VL-7B 正是在这样的现实背景下诞生的。它并非为了追求炫目的指标或短期展示效果,而是面向工程落地场景,提供一款可长期运行、可控、可部署的视觉+语言推理模型。
作为一款华为昇腾原生开源的 7B 参数多模态模型,openPangu-VL-7B 聚焦视觉定位、OCR 与文档理解等核心能力,面向端侧与边缘计算场景,在昇腾 Atlas 系列硬件上实现接近实时的推理性能。在架构与训练层面,模型从底层视觉编码到高层语义理解进行了针对性优化,使其在真实业务场景中既高效,又具备良好的稳定性与可预期性。
? 立即体验:
https://ai.gitcode.com/ascend-tribe/openPangu-VL-7B/model-inference
多模态落地的现实困境
与 openPangu-VL-7B 的出发点
在产业级应用中,多模态模型通常需要稳定支撑三类核心需求:视觉定位、OCR 与文档结构理解,以及跨模态问答与逻辑推理。
但在实际落地过程中,这些能力在多数开源多模态模型上,往往会集中暴露出三类问题:
稳定性不足:同一图像在多次推理中输出结果波动明显,难以沉淀为可复用、可自动化的业务流程;
可控性不强:在复杂视觉场景下,OCR 与定位结果容易出现误读或自行补全,增加人工校验与风险控制成本;
工程成本偏高:在 GPU 或通用算力平台上部署,多模态模型推理开销大,不利于长期、高频的业务调用。
openPangu-VL-7B 的设计正是围绕这些现实约束展开。它的目标并非追求单次推理效果的“惊艳”,而是在工程级场景中提供稳定、可控、可持续运行的多模态能力。通过专为昇腾硬件架构设计的网络结构与训练策略,它在实际运行效率和推理稳定性上展现出明显优势。
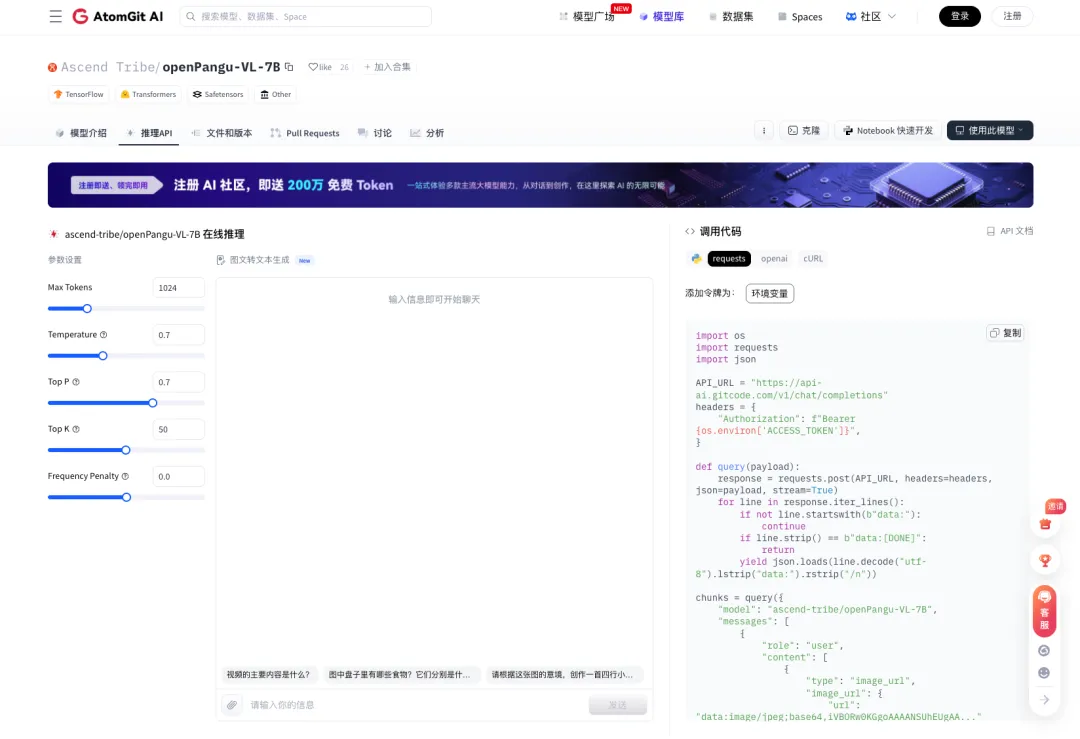
下面我们在 AtomGit AI 对 openPangu-VL-7B 进行在线体验,重点考察模型在真实使用场景下的视觉理解能力。
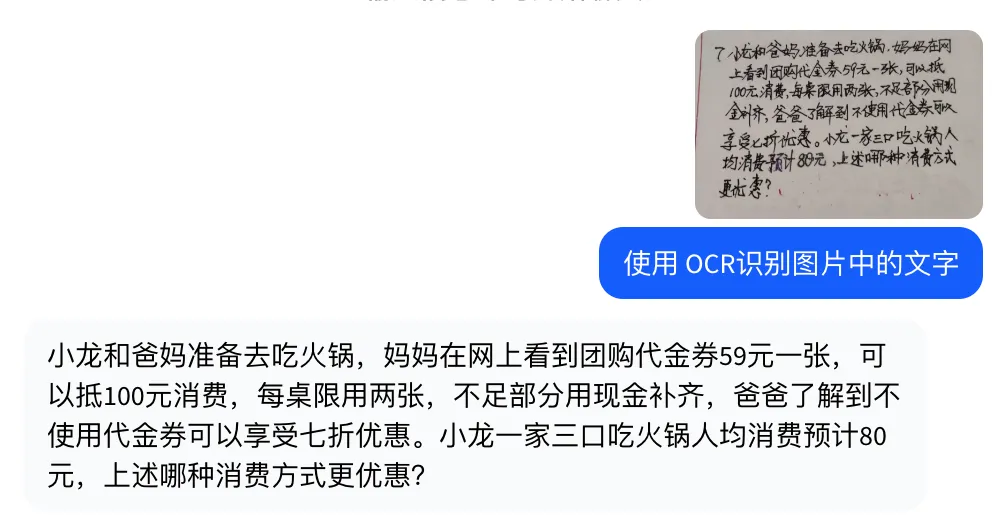
手写文本识别
首先测试的是手写内容识别:在压缩拍摄、笔迹不规范的情况下,模型能否直接识别手写文本、保持较高准确率,并在无需额外预处理的前提下,正确还原关键信息与语义内容。
从结果来看,openPangu-VL-7B 能够稳定识别手写内容,对字形模糊、行距紧凑的输入也具备较好的容错能力,输出结果清晰且可直接使用。
找不同
接着我们测试了图片差异识别能力:给模型两张内容高度相似的图片,看看它能否把所有不同点都找出来。这类任务对视觉细节的把握要求很高,一旦定位不准,就很容易漏掉关键差异。
从实际结果来看,openPangu-VL-7B 能够准确识别两张图片之间的差异点,未出现明显漏检或误判,整体判断过程稳定,输出结果清晰可复用。

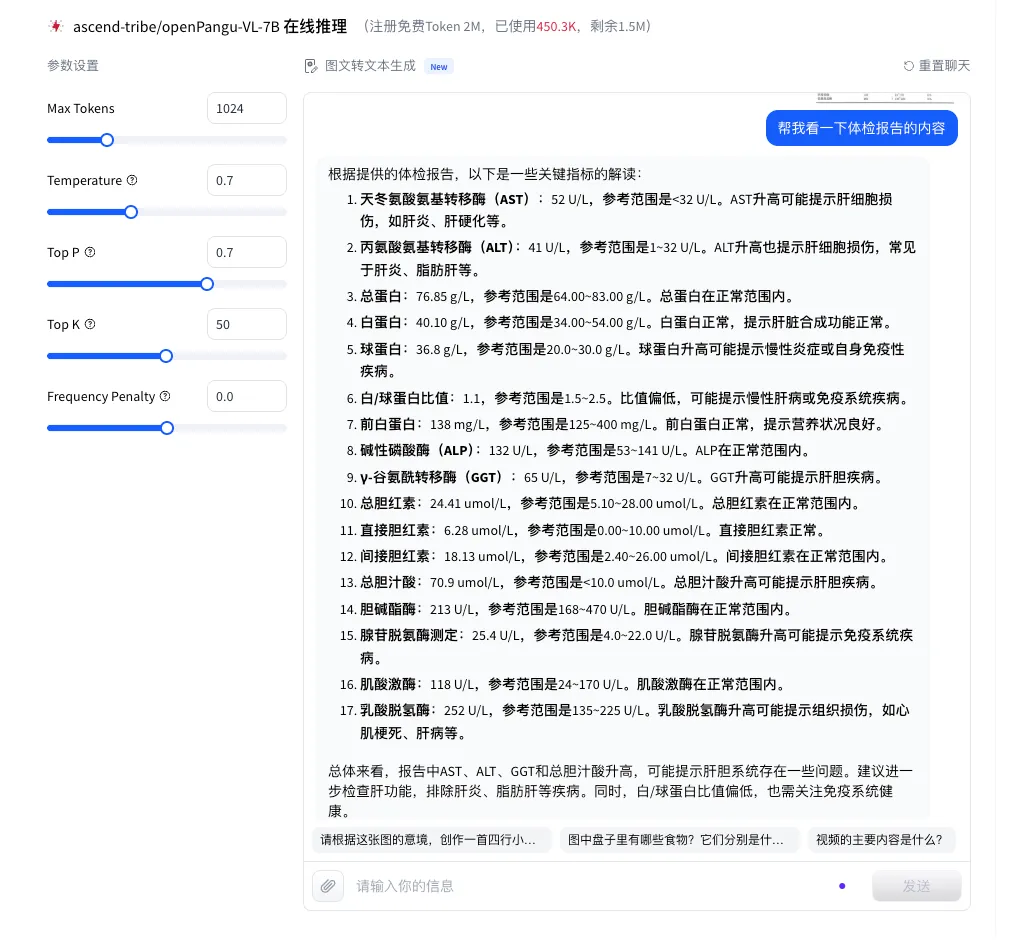
报告分析
接下来测试的是报告理解与分析能力:我们上传了一份体检报告,主要想看看模型能否真正“读懂”报告内容,而不是只停留在简单的文字识别层面。重点关注两点:一是对指标含义的理解是否准确,二是能否结合常识给出合理的分析和注意事项。
在不额外提供背景说明的情况下,openPangu-VL-7B 能够抓住报告中的关键信息,对异常指标进行说明,并给出相对清晰、结构化的解读结果。同时,对需要关注的事项和生活建议也能给出明确提示,整体分析逻辑比较连贯,没有出现明显的误读或随意发挥。
综合多项在线测试结果,openPangu-VL-7B 在图像识别与多模态理解任务中表现稳定。无论是手写内容识别、图像差异判断,还是对体检报告等复杂文档的分析,模型都能够准确提取关键信息,并给出结构清晰、逻辑一致的输出结果。整体来看,该模型在多模态理解的准确性、稳定性和工程可用性方面具备较好的表现,适合在实际业务场景中长期使用。
面向真实场景的典型应用案例
openPangu-VL-7B 在多个实际业务场景中体现出较强的落地适配性,整体表现偏稳定、可控,适合直接接入现有流程使用。
工业质检
在昇腾 Atlas 800T A2 环境下,模型能够对产线图像完成缺陷定位与内容理解,推理过程稳定,连续处理过程中未出现明显丢帧或结果波动。整体体验更偏向工程可用,而不是单次测试效果:

财报截图与文档结构提取
将财务报表截图输入模型后,openPangu-VL-7B 能够识别表格结构,并输出结构清晰的 Markdown 结果。行列关系保持准确,缺失项和异常位置也较容易被识别,基本可以直接用于后续整理或复核。
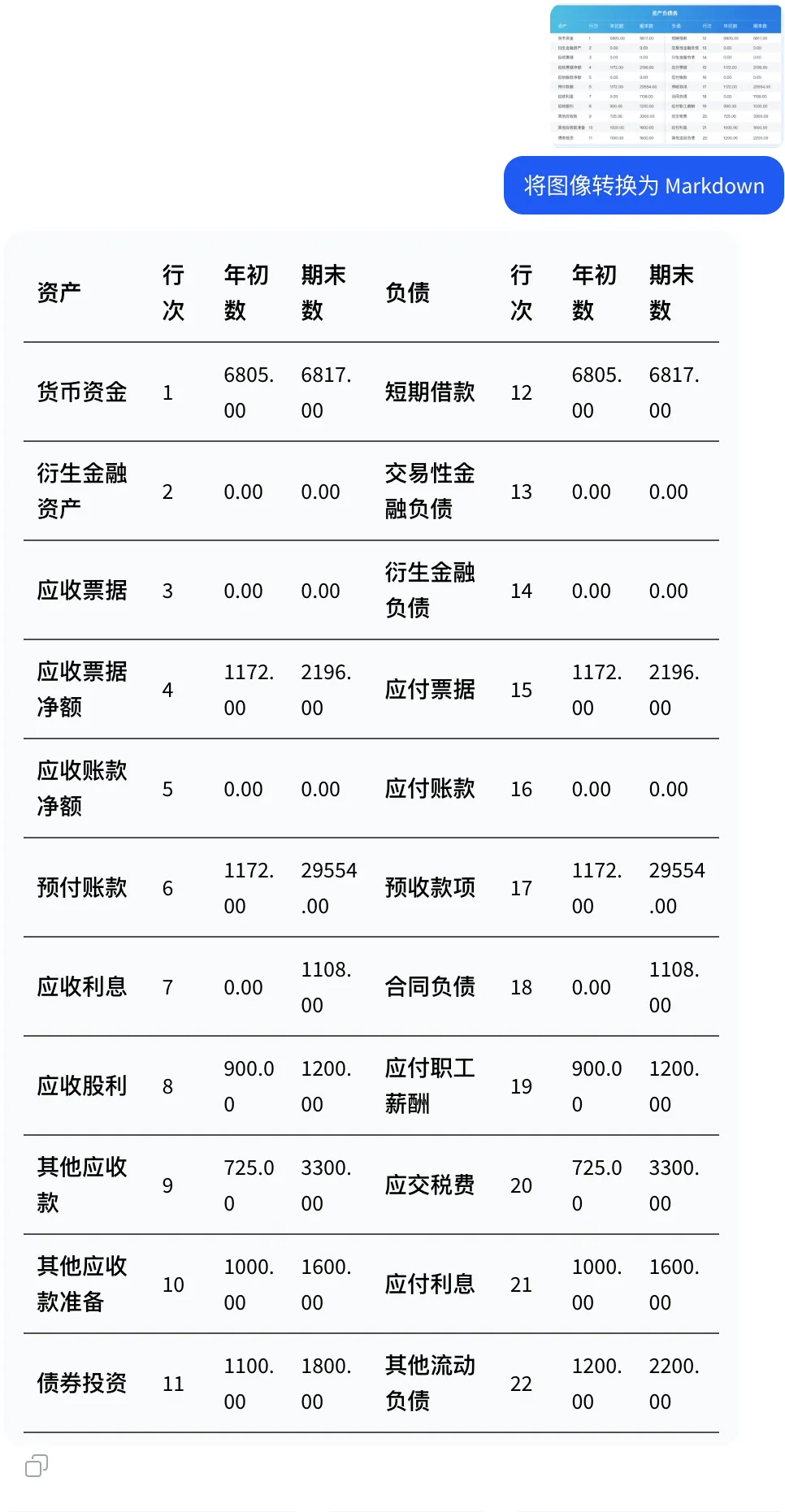
在实际测试中,我们将多张财报截图交由模型处理,并要求其转换为 Markdown 格式,输出结果与原始表格结构一致,能够满足日常文档处理需求。
教育试卷与手写批改
在试卷和手写作业场景中,模型可以识别学生的手写答案并进行区域定位,减少人工框选和标注的工作量。老师只需在结果基础上进行简单核对,而无需逐项手动处理,有助于提升批改效率。

综合来看,openPangu-VL-7B 在工业质检、文档处理和教育场景中都表现出较好的实用性。在产线图像与连续推理任务中,模型运行稳定、结果一致,具备工程级可用基础;在财报截图与文档结构提取场景下,能够准确还原表格结构,输出结果可直接用于整理与复核;在试卷与手写内容处理中,则有效降低了人工标注与框选成本,提升了整体处理效率。整体体验更偏向真实业务落地,而非仅在单次测试中追求效果表现。
快速体验模型能力
为了帮助用户快速上手并高效评估模型能力,openPangu-VL-7B 提供 在线体验 与 API 接入 两种使用方式,分别面向快速验证与工程化应用场景。
方式一:即刻在线体验
无需部署,无需环境配置,打开即可使用。
通过模型在线推理页面上传图片并输入提示语,即可直观体验 openPangu-VL-7B 在多模态内容理解与生成方面的实际效果,适用于模型能力验证、场景测试以及不同模型之间的对比评估。
? 在线体验地址:
https://ai.gitcode.com/ascend-tribe/openPangu-VL-7B/model-inference
方式二:调用推理 API
还可通过推理 API 接入模型能力,完成多模态推理任务,适用于多模态应用开发、自动化流程集成,以及对推理性能要求较高的工程场景。
? 推理 API 地址:
https://ai.gitcode.com/ascend-tribe/openPangu-VL-7B/model-inference

推荐阅读

G-Star 精选开源项目推荐|第六期

城市坐标计划|全国Meetup合作社区招募中!

