

本文构建了端到端神经网络模型预测AH同时上市企业溢价变化方向。截至2025年年底,全市场已近170家企业实现AH两地上市,将近100家为沪深300指数成分股。大陆机构投资者对于港股的投资理念也有所转变。A/H股轮动或将成为一部分主动权益基金、量化基金的超额收益来源。由于两地股票的基本面没有差异,所以建模的重心放在量价和估值特征上。基于精巧的配对样本、模型结构、损失函数设计,我们构建了一个年化超额收益约为5%的A/H股轮动模型,应用于沪深300指增也有所增益。
样本设计:需对齐A/H股交易日,并进行合理的数据增强
本研究将配对的一组A股和港股视为一个样本。针对A股和港股交易日期不完全重合的问题,处理原则是保证A股和港股特征和标签的时间跨度一致。其中,特征跨度60个沪深港通交易日,标签跨度20个沪深港通交易日。针对AH同时上市企业数目较少、样本量可能不够的问题,将AH同时上市企业两两配对,并使用DTW距离评价假样本的相似度,然后在每一个截面上,都按照DTW距离从小到大的顺序,取真样本数量4倍的假样本。
模型结构:关注A股与港股的相对涨幅,剔除市场Beta的干扰
模型结构包括特征提取模块和溢价预测模块。特征提取模块的主体结构是共享参数的GRU单元、自注意力机制/交叉注意力机制单元。将A股和港股经标准化后的量价和估值比数据分别输入相同的特征提取模块,各自得到一组高阶特征。溢价预测模块将A股和港股对应的高阶特征两两相减后,输入全连接层,预测未来20个沪深港通交易日A股与港股的相对涨幅。特征提取模块的共享参数配合溢价预测模块的特征相减,既能够将与AH溢价关系不大的市场Beta抵消掉,又能够节省一半的参数。损失函数结合胜率视角的二分类交叉熵和赔率视角的均方误差构建。
回测结果:本质是择时问题,模型表现可能与大盘整体AH溢价水平有关
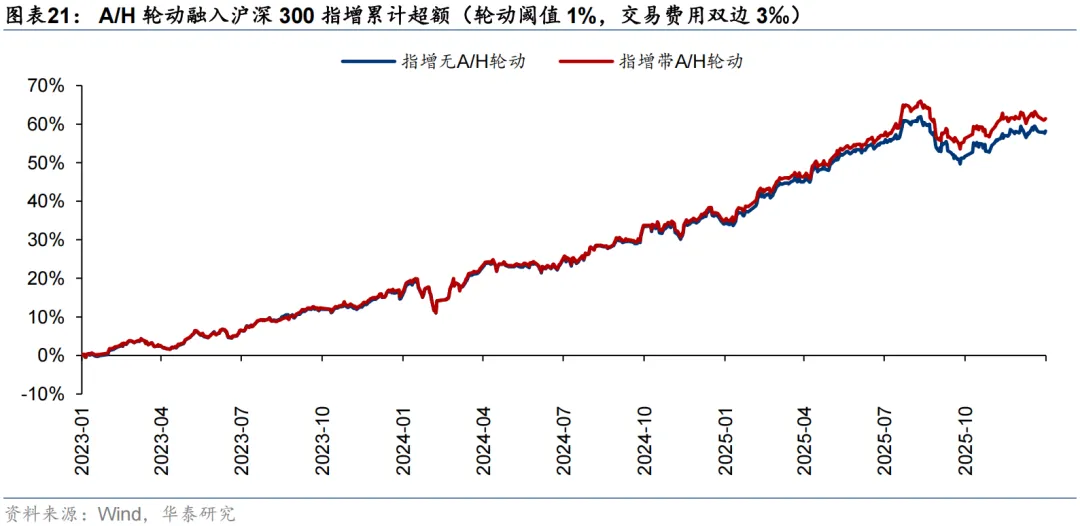
周度A/H股轮动测试设置了轮动阈值。对于一个AH同时上市企业,只有当模型预测得分高于轮动阈值,才会开展A/H股轮动;否则,考虑到交易费用限制,将维持A/H股等权持有。结果显示,不同轮动阈值下轮动策略的年化超额收益均在5%左右,轮动阈值没有对策略表现形成显著影响,更多体现了收益和换手之间的权衡。将A/H轮动信号应用于PorfolioNet 2.0的沪深300指增策略,考虑双边3‰的手续费用后,年化超额收益提升了0.84 pct。我们还发现,自2024Q3以来,南向资金加速流入,大盘整体的AH溢价水平迅速下降,轮动机会变少,模型获取超额收益的难度大幅增加。
01 研究背景
作为中国资本市场双向开放的重要产物,AH两地同时上市企业已形成规模效应与行业影响力。自2015年以来,AH两地上市模式持续扩容;截至2025年年底,全市场已近170家企业实现AH两地上市,将近100家为沪深300指数成分股,涵盖大金融、大制造、医药生物、信息技术等关键领域,既是实体经济的支柱力量,也是跨境资本流动的重要载体。

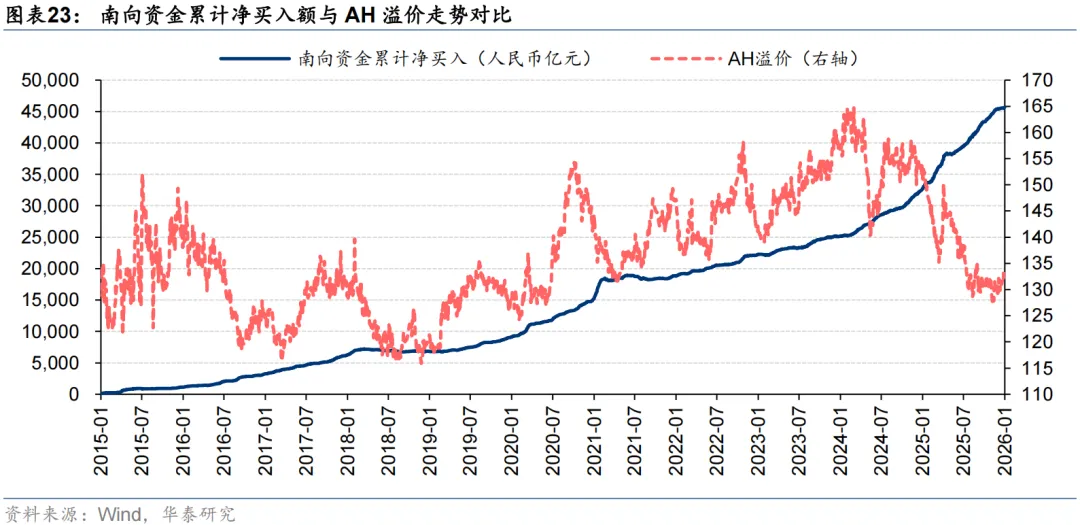
近一年多时间内,A股龙头企业的加入,不仅丰富了港股市场结构,更推动了两地估值体系的深度融合,部分优质标的甚至出现H股价格超越A股价格的“溢价倒挂”现象,反映出国际资本对中国核心资产的认可,毕竟由于港股红利税的存在,A股价格高于H股价格才是常态。同时,境内投资者在港股定价中的“话语权”有所提升。截至2025年年底,南向资金持有港股总市值超过6万亿港元,超过港股流通市值的15%,较2024年年底的占比提升约4 pct。
在两地互联互通蓬勃发展的背景下,一个与两地投资者切身利益相关的问题接踵而至:如果看好一家AH两地同时上市企业,究竟买A股还是买港股?A/H股轮动或将成为一部分主动权益基金、量化基金的超额收益来源。对此,本文将构建一个端到端神经网络模型来预测AH两地同时上市企业的溢价变化方向。由于两地股票的基本面没有差异,所以建模的重心将放在量价和估值特征上。后文分为三部分——样本设计、模型结构、回测结果,其中回测包括AH轮动测试和沪深300指增测试。
02 样本设计
将配对的一组A股和港股视为一个样本。在建模之前有两个问题需要解决:
1)A股和港股交易日期不完全重合,有可能导致AH信息错位;
2)AH同时上市企业数目较少,对于神经网络训练来说有可能样本量不够。
A/H股交易日处理
针对第一个问题,我们的处理原则是保证A股和港股特征和标签的时间跨度一致。假设站在2025-10-09开盘前,前推60个AH公共交易日即沪深港通交易日来到2025-07-09,我们将2025-07-09至2025-10-09开盘前A股和港股的全部量价信息作为特征;后推20个沪深港通交易日来到2025-11-06,我们将2025-10-09至2025-11-06期间以VWAP计算的A股收益率和港股收益率之差作为标签。在这个例子中,A股和港股的特征的真实长度不相等,A股的特征长度不是60个A股交易日,港股的特征长度也不是60个港股交易日;A股和港股的标签的真实长度也不相等,A股的标签长度是21个A股交易日;但信息的时间跨度是一致的。顺便提及,GRU作为一类循环神经网络,可以处理非等长的特征序列。

数据增强:训练过程中补充真样本数量4倍的假样本
针对第二个问题,制造假样本是一种常见的数据增强手段。在图像识别领域中,研究人员通常通过对图像进行翻转、旋转来制造样本。在本研究中,我们将AH同时上市企业两两配对,如将企业X的A股和企业Y的港股配对,从而得到N×(N-1)个假样本,N为AH同时上市企业数量。
不过,本研究建模无法使用全部的假样本,而只能使用其中一部分“逼真”的假样本。在真样本中,A股和港股的走势是比较相似的。我们希望GRU模型能实现类似游戏《大家来找茬》的效果,从两幅相似的走势图中找到影响AH溢价变化的关键因素。让“一眼假”的假样本参与模型训练,反而可能会阻碍模型“找茬”能力的提升。
对此,我们用DTW距离来刻画每一个假样本的相似度。在《行业配置策略:中观景气视角(2)》(2022-07-18)、《中国PPI的Nowcasting与通胀敏感型行业轮动》(2024-12-06)等前期报告中,我们就详细介绍过DTW算法,并用DTW距离来刻画两个宏观/中观指标之间的相似度。只不过宏观/中观指标都是以一维时间序列呈现,而本研究中A股和港股的走势以OHLCV的多维时间序列呈现,因此距离的定义有所差异。
具体来说,求解DTW距离的过程等价于求解棋盘上的旅行商问题。其中,棋盘的i轴对应A股,i轴的长度等于A股特征的真实长度;j轴对应港股,j轴的长度等于港股特征的真实长度。每一个棋盘格子(x,y)都有一个距离dx,y,等于A股的第x根K线和港股的第y根K线之间的欧氏距离;在计算一维时间序列的相似度时,这里的距离等于序列A的第x个数和序列H的第y个数之差的绝对值。棋子从棋盘左下角起点走到右上角终点,且只能往↑/↗/→三个方向走,请问最短路径是哪一条?这是一个典型的动态规划问题。在用动态规划计算出最短路径之后,最短路径所经过的全体棋盘格子dx,y的均值,就是DTW距离。其数值越小,就表明两张K线图长得越像。
相似K线图本就是DTW算法在金融领域中的较早应用之一。而且和GRU一样,DTW算法也可以用于计算非等长时间序列的相似度。左下图中是一个求解等长时间序列DTW距离所需的棋盘,是一个正方形的棋盘;而右下图中在求解非等长时间序列DTW距离时,只需要将正方形的棋盘改成长方形的棋盘即可,求解最短路径的过程完全相同。
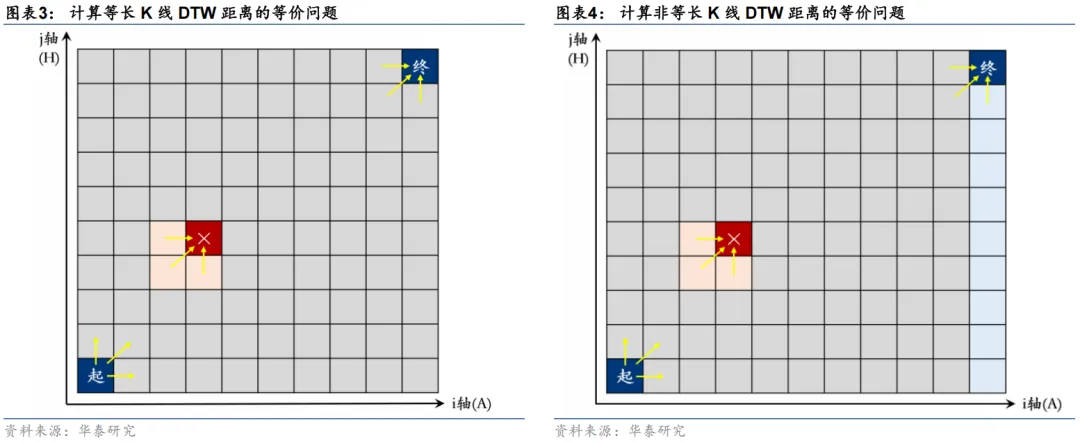
需要强调的是,无论是计算DTW距离之前,还是作为神经网络的输入特征,A股和港股的量价信息都要先进行标准化处理。
本研究采用的标准化方式与交易软件的标准化方式类似。在交易软件中,不管我们截取哪一段K线,它都会将其缩放至屏幕的大小。具体来说,对于OHLC,我们将K线片段中最低价的最小值视为0,将最高价的最大值视为1,进行0-1标准化;对于成交额/换手率,将每天的成交额除以K线片段中成交额/换手率的最大值,进行归一化。需要注意的是,港股日K线中的价格信息在标准化之前需要乘以港元兑人民币汇率。港股通交易使用的结算汇率主要参考离岸价格,但港元兑离岸人民币(Wind代码HKDCNH.FX)序列较短,所以我们用港元中间价(Wind代码HKDCNY.EX)序列近似替代。
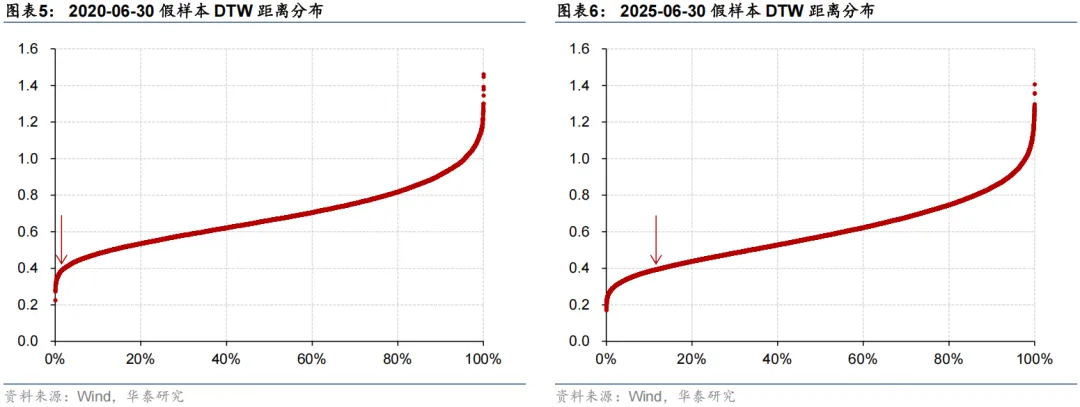
用经过标准化后的时间序列计算DTW距离,DTW距离的数理意义更明确——两条时间序列的差异相当于自身波动的多少倍。DTW距离的经验阈值是0.5。在本研究中,绝大部分的假样本都是“一眼假”的,且“逼真”的假样本数量在不同截面之间差异较大。例如在2020-06-30这一截面,约12%的假样本DTW距离小于0.5、只有约2%的假样本DTW距离小于0.4;而在2025-06-30这一截面,约1/3的假样本DTW距离小于0.5、约13%的假样本DTW距离小于0.4。
经过尝试,我们最终在每一个截面上,都按照DTW距离从小到大的顺序,取真样本数量4倍的假样本,这样能够保证绝大部分假样本的DTW距离小于0.4、全部假样本的DTW距离都小于0.5。
03 模型结构
我们最终确定了如下结构的GRU模型:
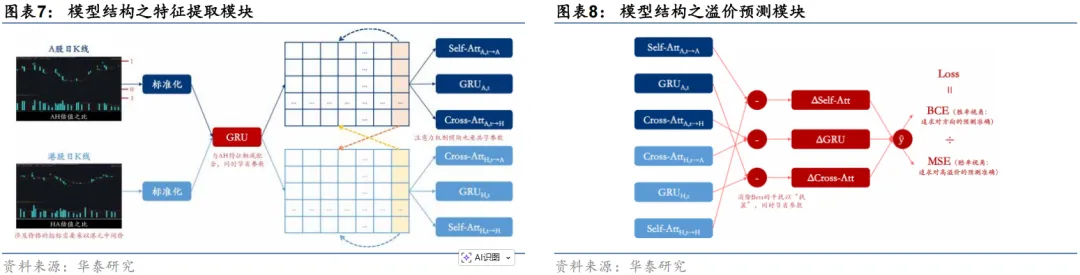
特征提取模块
在输入GRU单元之前,同一组样本内A股和港股的日K线需要进行标准化。标准化的方式与数据增强部分的做法一致。
估值是本研究为数不多的能够使用的基本面信息——在A股的标准化后量价信息之上,进一步叠加A股市值除以港股市值的序列;在港股的标准化后量价信息之上,进一步叠加港股市值除以A股市值的序列,以保证A股和港股初始特征维度一致。
经过GRU单元的处理,A股和港股分别得到了高维隐含特征的时间序列,进一步将其处理为三类特征:1) GRU单元最后一个时刻输出,2) A股/港股以最后一个时刻输出为Q、以其自身全历史为K/V的自注意力机制单元输出,3) A股/港股以最后一个时刻输出为Q、以港股/A股全历史为K/V的交叉注意力机制单元输出。引入交叉注意力机制单元,是为了引入A股和港股信息的交互。
其中,GRU单元、自注意力机制/交叉注意力机制单元对于A股和港股是共享参数的,具体原因详见后文。
溢价预测模块
提取特征之后,我们将A股的三类特征与港股对应的三类特征相减。这一步的目的是为了将刻画A股和港股共同走势的特征即市场Beta抵消掉,因为模型的预测目标不是某只股票未来20个沪深港通交易日的涨跌幅,而是未来20个沪深港通交易日该企业的A股比港股多涨了多少。也正因为特征相减,特征提取模块的GRU单元和注意力机制单元需要共享参数——如果A股和港股采用独立的GRU单元或注意力机制单元,参数初始化难免会引入噪声,而这些噪声无法靠减法抵消掉。而且,采用共享参数还有一个好处,就是可以节省一半的参数,对于本研究这个小样本预测问题来说,能降低过拟合风险。
最后,我们将相减后的三类特征通过全连接层给出最终的预测得分。本研究的首要任务是要判断一家AH同时上市企业在未来一段时间中是A股占优还是港股占优,是一个分类问题。因此,损失函数的关键项应是二分类的交叉熵(BCE)。不过,BCE是胜率视角的损失函数,其对待溢价变化方向相同但变化幅度不同的两个机会是一视同仁的。而投资者在实际投资中肯定更希望能够把溢价变化幅度更大的机会即高赔率机会抓住。对此,损失函数还需要引入赔率视角的均方误差(MSE)作为辅助。考虑到BCE和MSE的梯度不在同一个数量级上,等权相加可能并不合适,我们最终采用的方式是两者相除——由于BCE非正,随着MSE变小,损失函数会负得越多:
Loss = BCE / MSE
模型超参一览
本研究从2020-12-31开始,每隔半年重新训练一次模型,并应用于接下来半年的测试:

04 策略回测
A/H股轮动测试
A/H股轮动测试中全体AH同时上市企业等权买入,周度再平衡。每周第一个交易日开盘前将全体最新的A/H股量价和估值比数据输入最新一期重训练后的模型,得到AH溢价的预测值。当某一个企业的预测值大于阈值x时,模型判断未来该企业的A股将占优,策略将该企业的仓位全部买入对应的A股;预测值小于阈值-x时,模型判断未来该企业的港股占优,策略将该企业的仓位全部买入对应的港股;预测值介于-x和x之间时,模型判断未来该企业的A股和港股没有显著差异,策略将该企业的仓位等权买入对应的A股和港股。基准为各企业的仓位每周都等权买入对应的A股和港股。交易采用当天的VWAP完成。
轮动阈值x取了1%/2%/3%/4%/5%分别测试。之所以设置轮动阈值,是因为交易存在手续费,如果预测的AH溢价空间连双边手续费都无法覆盖,那这样的交易是没有意义的。其中港股通的手续费还要更贵一些,包括固定税费和券商佣金,券商佣金由协商确定,固定税费又包括印花税、交易费、交易征费、股份交收费、证券组合费等,合计约双边3‰。
测试区间设定为2021至2025共5年。从回测来看,模型的超额收益较为稳定。随着轮动阈值x的提升,因可交易机会数量下降,年化超额收益从x=1%时的5.61%下降到x=5%时的4.43%,但年化单边换手也从7.61倍下降到5.66倍。可见轮动阈值x非敏感参数,不同的x没有对策略表现形成显著影响,更多体现了收益和换手之间的权衡。
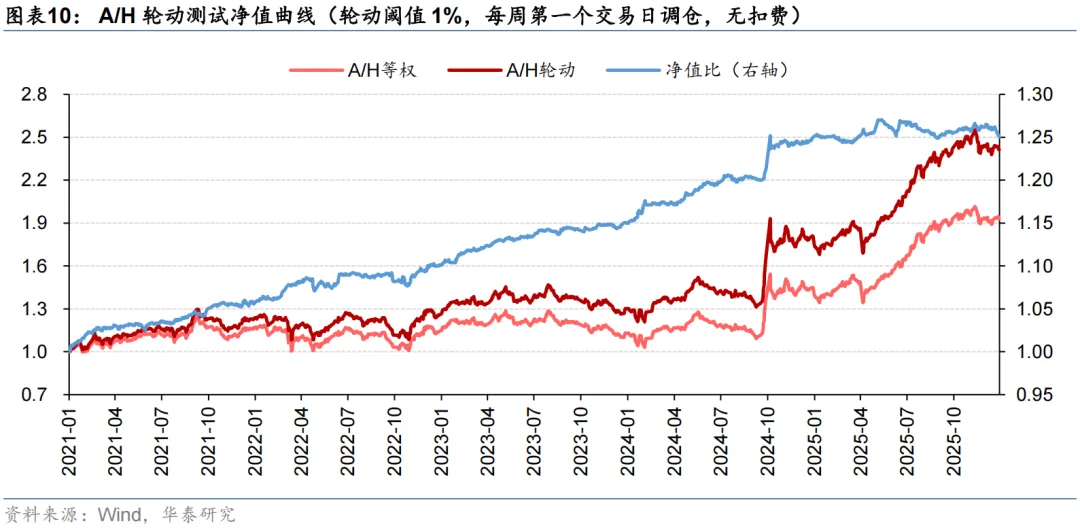
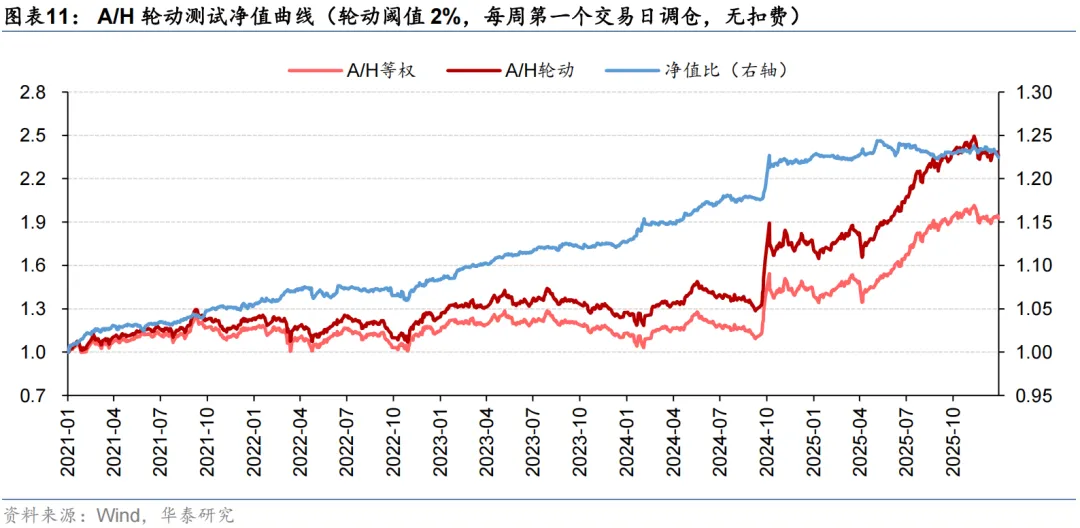
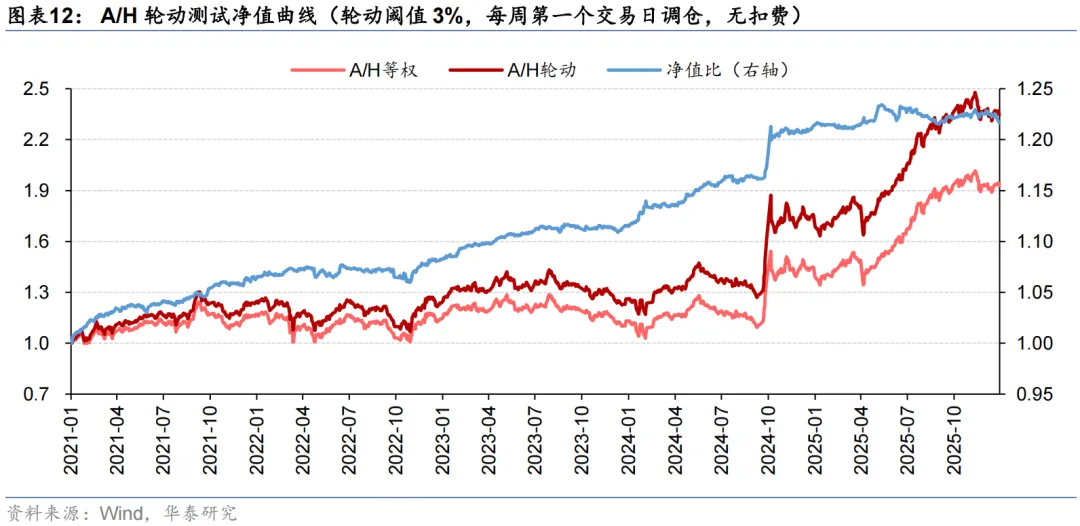
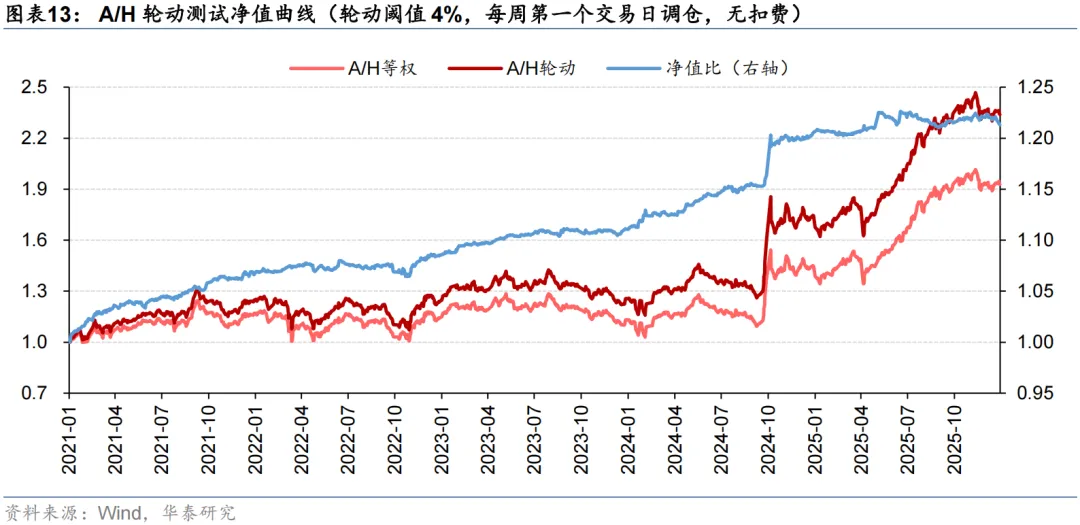
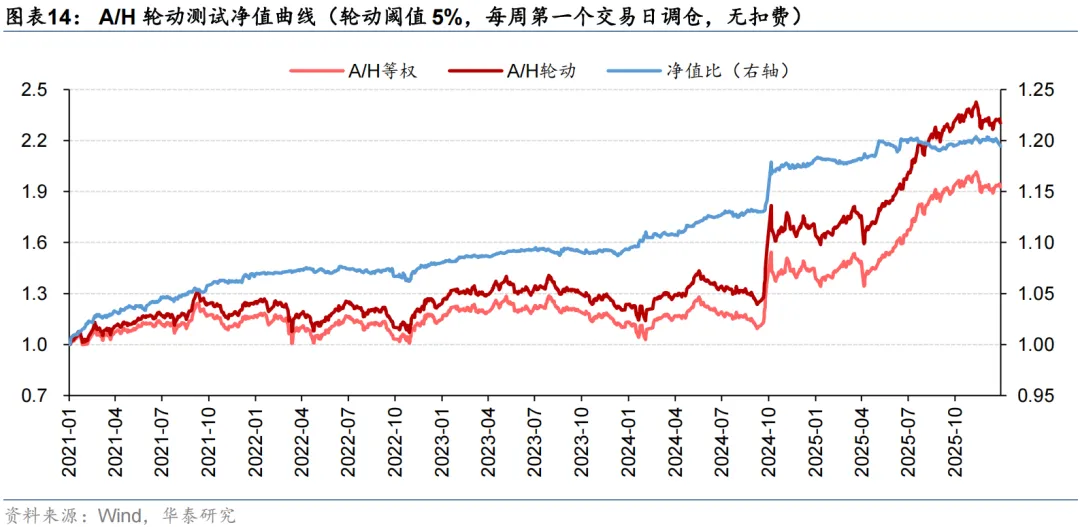
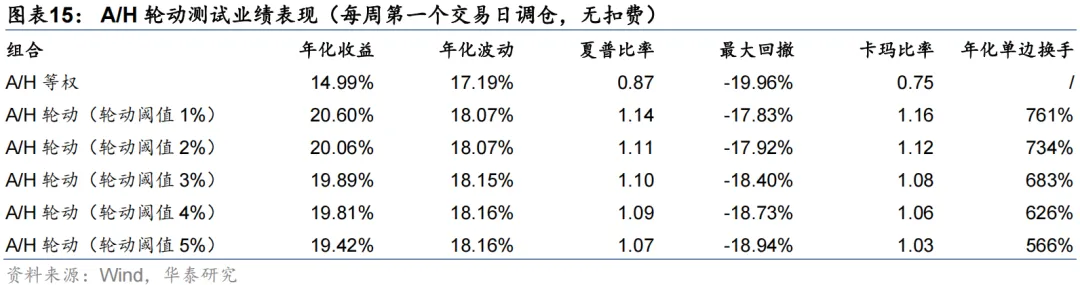
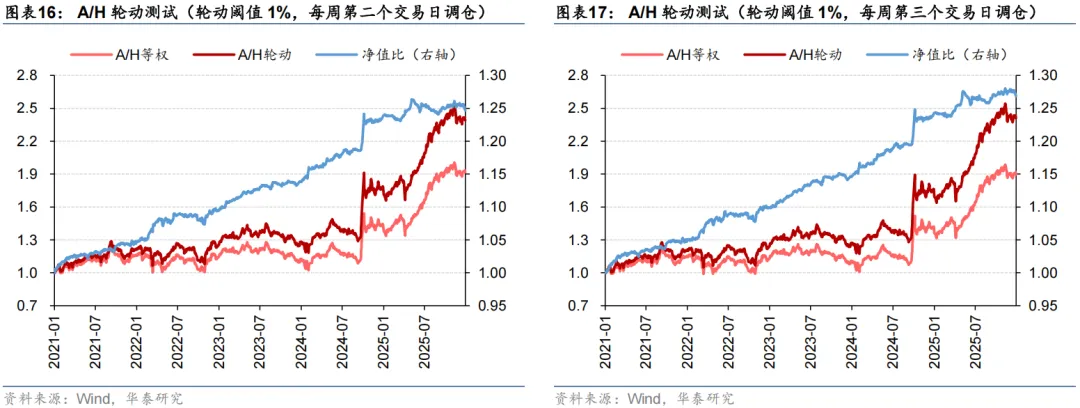
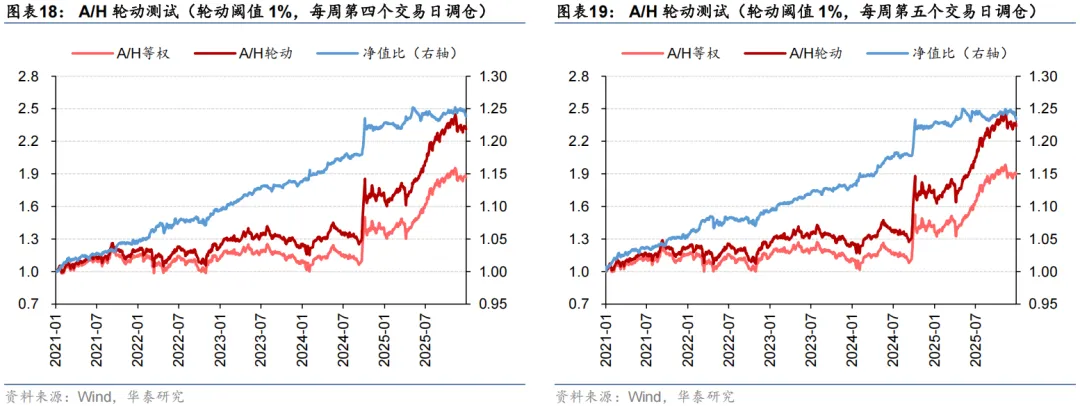
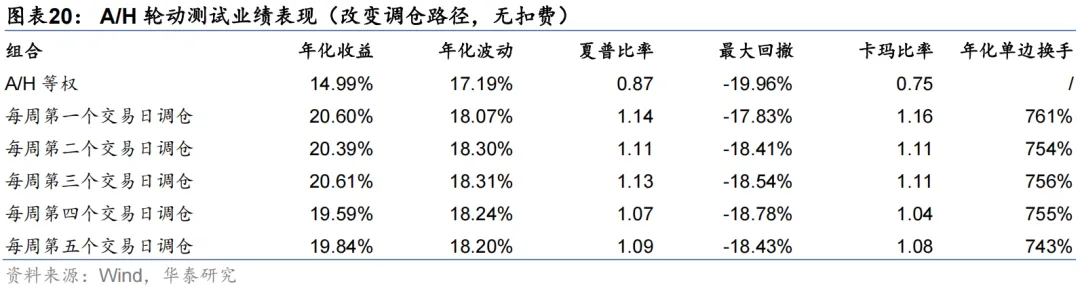
出于对调仓路径依赖的担忧,我们以x=1%为例,进一步将调仓日期改为每周第二/三/四/五个交易日,开展A/H股轮动测试。结果显示,调仓路径也未对模型表现造成显著影响。
沪深300指数增强测试
前期报告《PortfolioNet 2.0:如何兼取风格收益与Pure Alpha》(2025-12-16)对内置组合优化器的端到端神经网络进行了升级,不再将风格Beta以外生输入的形式输入给组合优化器,而是让神经网络同步学习股票Alpha和风格Beta,有利于提纯Alpha。考虑双边3‰的交易费用,在2023至2025共3年时间内,基于该模型构建的周频调仓的沪深300指数增强策略相对沪深300价格指数年化超额收益为17.79%。沪深300指数的成分股中有将近100个企业AH同时上市,所以我们进一步考虑用A/H股轮动来进一步提升沪深300指增的超额收益。
仍然设置轮动阈值x=1%。初始状态是指增组合中所有企业的仓位都是A股仓位。当某企业AH溢价预测值小于-1%时,就将指增组合中该企业对应的A股仓位替换为港股仓位;在持有港股仓位后,当AH溢价预测值回升至1%以上时,就将港股仓位替换为A股仓位;当AH溢价介于±1%之间时,如前文所述,信号的置信度有限,故不做轮动。
同样考虑双边3‰的交易费用,结果显示,融入A/H股轮动信号后,沪深300指增年化超额收益小幅提升0.84 pct,信息比率、超额最大回撤、超额卡玛比率均有小幅改善,当然年化单边换手也小幅提升了1.43倍。
不过实战中,将A/H股轮动应用于指增产品会面临以下阻力,本研究暂时无法解决:
1)卖出港股后资金T+2到账;
2)港股通交易的汇率保证金会占用一部分仓位;
3)持有指数成分股对应的港股视作成分外股票。

本研究与选股的本质区别
从前文的测试中,不难发现自2025Q2以来,模型获取超额收益的难度大幅增加。这有可能是因为最近一年多,大陆的机构投资者对于港股的投资理念有所转变,神经网络没有充足的样本学习到投资逻辑的变化。但我们认为更有可能的原因在于2025Q2以来,港股相对A股显著占优的机会数量迅速下降。自2024Q3以来,南向资金加速流入,大盘整体的AH溢价水平迅速下降,来到了近五年的低位。
本研究和选股不同。选股是一个截面比较问题,不管大盘行情如何,总能找到一批股票跑赢大盘。而本研究本质上是一个择时问题,只有当市场上普遍存在港股相对A股显著占优的机会,模型才有可能抓到A/H股轮动的机会,所谓“巧妇难为无米之炊”。未来某一天当大盘整体的AH溢价水平回升至高位时,本研究的用武之地会更加广阔。
风险提示
1) 端到端神经网络在滚动窗口中挖掘历史规律,规律可能会在下次重训练之前失效;
2) 端到端神经网络作为一类机器学习方法,可能存在过拟合问题;
3) 量价模型有其适用的市场条件,无法保证在任何市场条件下均可取得超额收益。
相关研报
研报:《AH同时上市企业溢价变化方向预测》2026年1月22日
研究员:徐 特 S0570523050005
研究员:何康 S0570520080004丨BRB318
联系人:孙浩然S0570124070018
关注我们
https://inst.htsc.com/research
访问权限:国内机构客户
https://intl.inst.htsc.com/research
免责声明
▲向上滑动阅览
本公众号不是华泰证券股份有限公司(以下简称“华泰证券”)研究报告的发布平台,本公众号仅供华泰证券中国内地研究服务客户参考使用。其他任何读者在订阅本公众号前,请自行评估接收相关推送内容的适当性,且若使用本公众号所载内容,务必寻求专业投资顾问的指导及解读。华泰证券不因任何订阅本公众号的行为而将订阅者视为华泰证券的客户。
本公众号转发、摘编华泰证券向其客户已发布研究报告的部分内容及观点,完整的投资意见分析应以报告发布当日的完整研究报告内容为准。订阅者仅使用本公众号内容,可能会因缺乏对完整报告的了解或缺乏相关的解读而产生理解上的歧义。如需了解完整内容,请具体参见华泰证券所发布的完整报告。
本公众号内容基于华泰证券认为可靠的信息编制,但华泰证券对该等信息的准确性、完整性及时效性不作任何保证,也不对证券价格的涨跌或市场走势作确定性判断。本公众号所载的意见、评估及预测仅反映发布当日的观点和判断。在不同时期,华泰证券可能会发出与本公众号所载意见、评估及预测不一致的研究报告。
在任何情况下,本公众号中的信息或所表述的意见均不构成对任何人的投资建议。订阅者不应单独依靠本订阅号中的内容而取代自身独立的判断,应自主做出投资决策并自行承担投资风险。订阅者若使用本资料,有可能会因缺乏解读服务而对内容产生理解上的歧义,进而造成投资损失。对依据或者使用本公众号内容所造成的一切后果,华泰证券及作者均不承担任何法律责任。
本公众号版权仅为华泰证券所有,未经华泰证券书面许可,任何机构或个人不得以翻版、复制、发表、引用或再次分发他人等任何形式侵犯本公众号发布的所有内容的版权。如因侵权行为给华泰证券造成任何直接或间接的损失,华泰证券保留追究一切法律责任的权利。华泰证券具有中国证监会核准的“证券投资咨询”业务资格,经营许可证编号为:91320000704041011J。
