
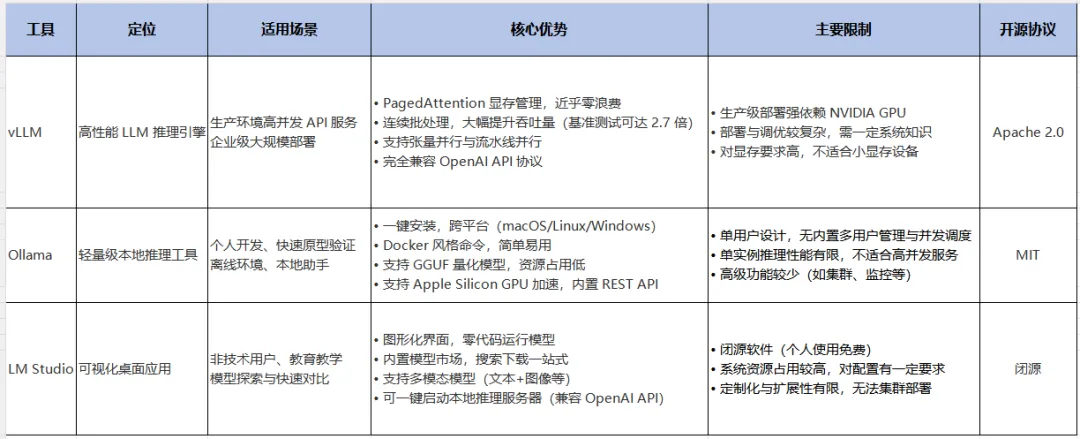
个人/小课题组本地部署大模型,为什么我首推 Ollama?(附主流模型清单)
如果你只有一张消费级显卡,又想把大模型真正用起来,Ollama 可能是眼下最省心的选择。
算力先上桌:32G 显存起步是“甜点”,小卡也能玩
很多朋友问我:本地部署大模型到底要什么显卡?
简单粗暴地说,想要比较舒服地跑起当前主流的“大家伙”,32G 显存是一个很好的起点。比如 NVIDIA V100 32G、A10 24G 或者 3090 24G 这类卡,通过量化就能把 30B+ 的模型稳稳塞进去,做知识库问答、论文润色、代码辅助都相当流畅。
但如果你手上只有一张 4060 Ti(16G 版) 这类甜品卡,也完全不用灰心。
虽然它跑不动巨型模型,但部署 12B 左右的轻量模型完全没问题,响应速度够快,搭一个内部用的智能客服、助教机器人绰绰有余。
划重点:不必追求一步到位,先让模型在本地跑起来,创造实际价值,再根据需求升级硬件也不迟。
Ollama 上的主流本地模型,这些“选手”值得关注
Ollama 之所以在个人和小课题组里越来越香,很大原因在于它几乎把下载、量化、部署的脏活累活都帮你干了。目前社区里 活跃度最高、实测体验最好的几款模型 大致如下:
- Qwen3.6-27B (通义千问3):实测目前ollama小模型阵营中最能抗打的生产力模型了,接入cc既可以写代码,也可以执行分析数据。27B 的参数规模,加载到显存占用24G左右,剩下8G左右的空闲,足够支撑一个课题组的输出了,但有一点需要明确:Ollama 默认是串行处理请求(来了一个请求处理完再处理下一个),不存在真正的并发。多人几乎同时提问,实际上是在排队,所以,这个时间等候问题大家在使用过程中需要注意到。
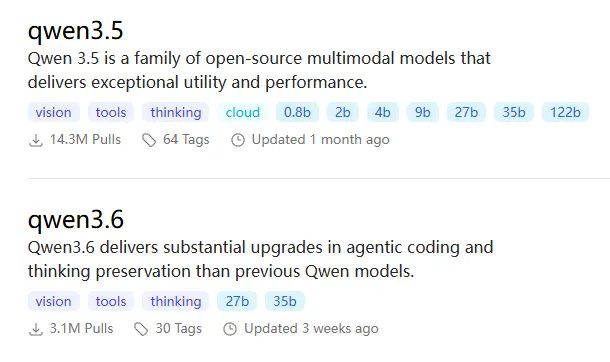 - Qwen3.6-35B:目前开源阵营的“六边形战士”,中英文均衡,指令跟随能力强,代码和长文本理解都拿得出手。35B 的参数规模,配合 4-bit 量化,一张 24G 显存的卡就能跑起来。实测感觉没有27B抗打,待后续继续对比看看。
- Qwen3.6-35B:目前开源阵营的“六边形战士”,中英文均衡,指令跟随能力强,代码和长文本理解都拿得出手。35B 的参数规模,配合 4-bit 量化,一张 24G 显存的卡就能跑起来。实测感觉没有27B抗打,待后续继续对比看看。
- Qwen3.6-35B-A3B(MoE 架构):总参数量 30B,但每次推理只激活约 3B,堪称“省显存神器”。在 Ollama 上运行后,你会发现它推理快、成本低,特别适合高频调用的业务场景,比如实时对话代理。但是,仅仅激活了很小部分参数,所以结果会大相径庭。
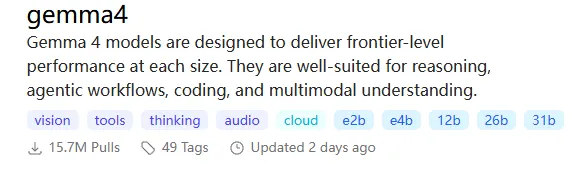
- Gemma 4 31B:Google 发布的新一代旗舰开源模型,纸面参数极强,支持推理、多模态、工具调用等高级特性。但在个人实际测试中,RTX 5090 32GB 运行默认配置已感吃力,显存几乎占满。更关键的是,目前将它接入cc做代码开发完全不可用—连基础的错误修正都无法完成,很可能是工具链适配还未跟上。建议:Gemma 4 更适合用于独立的对话测试或等待社区配套成熟。如果眼下急需在本地跑生产力代码任务,Qwen3.6-27B 仍然是首选,不仅显存占用友好,cc集成也经过了充分验证。
- Gemma 3 12B:如果你用的是 16G 显存的显卡,这是我会首推的小钢炮。12B 参数,推理飞快,写诗、总结、翻译、简单客服都不在话下,而且对 CPU 内存压力也小,Mac 用户同样能玩。
Ollama 的思路就是让你先把模型用起来、跑通场景,再慢慢迭代。从能做客服的小模型开始,到能啃论文、分析数据的 30B+ 大模型,这条路已经铺得足够平坦了。
你目前用 Ollama 部署的是哪个模型?体验如何?欢迎在评论区聊聊,咱们一起折腾,一起避坑。
或许有人会好奇:本地部署 GLM-5.2,可行吗?
先看参数:GLM-5.2,智谱的“远行时代”旗舰,支持 976K 超长上下文,参数规模高达 756B,刚刚更新,纸面上野心勃勃。
然后,咱们算一笔现实的账。
756B 参数,哪怕用最极端的 2-bit 量化(堪称弱鸡版),模型文件体积轻松超过 200GB。这已经远远超出了任何单张消费级显卡的显存上限— RTX 5090 才 32GB,这不是“压力很大”,是根本装不进去。
想要完整跑起来,显存必须能完整吃下这个 200GB+ 的巨兽。一张 NVIDIA Pro 6000 是 96GB 显存,一张 H200 是 141GB。你自己算:至少需要 2 张 Pro 6000,或者 2 张 H200,才能勉强把量化版塞进去。至于全精度版本?那更是不敢想。再乘以目前这些企业级显卡的售价—单张 H200 轻松六位数起步,两张就是一套小城市首付。这还没算服务器主板、电源、散热的成本。
所以,下次再有人轻飘飘地说“我在本地部署了 GLM-5.2”,你可以微微一笑,心里默算他的显卡账单。吹牛的成本,有时候就是一道小学数学题。
还没完,更刺激的来了:DeepSeek-V4-Pro
如果你觉得 756B 已经够夸张,来看看这个—DeepSeek-V4-Pro。两个月前更新,Mixture-of-Experts 架构,支持 100 万 token 上下文,参数总量达到惊人的1.6T(万亿)。
1.6 万亿参数是什么概念?即使它采用 MoE 架构,推理时只激活部分专家,但完整部署仍然需要装下全部参数。粗略估算,全精度需要约 3.2TB 显存,量化到 4-bit 也要接近 1TB。
用 H200(141GB 显存)来跑:至少需要 7 到 8 张。按照目前市场价格,这 8 张卡的硬件成本轻松突破七位数人民币。如果用 Pro 6000(96GB),则需要 10 张以上。
这已经不是“小课题组”的范畴了。这是一台小型超级计算机的配置,够一个中型公司搭建自己的私有化 AI 集群了。
