
Token制造探秘:剖析三大客户群体及生产线布局
作者:本站编辑
2026-06-24 10:36:47
0
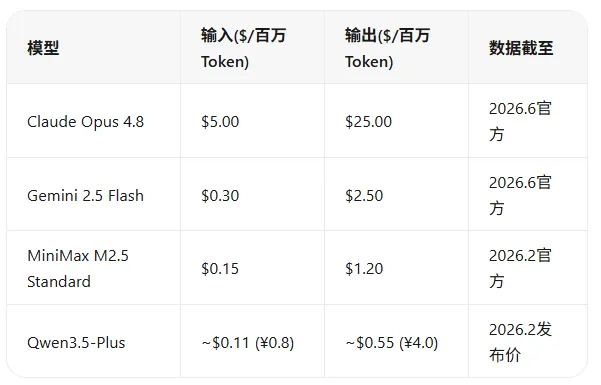
Token制造探秘:剖析三大客户群体及生产线布局2006年,亚马逊推出AWS的时候,企业的第一反应是"我的服务器凭什么放你那里"。十年后,没人自己建机房了,不是不想,是不划算。 2026年,Token生产面临同样的问题, 企业级用户对自身商业资产与商业安全的深切关注依旧没变,TONEN的生产投入与数据中心的投入差别是指数级的。怎么办? 2026年3月的英伟达GTC大会上,黄仁勋说了一句让整个行业跟着拐弯的话:数据中心已经从文件存储设施变成了Token生产工厂,未来每家公司都将以"AI工厂效率"来衡量竞争力。他把Token定义为一种新的大宗商品,和石油、电力同级别,TOKEN的生产需要工业级别的规模级工厂,方可满足可能指数级爆发的TOKEN需求。 TOKEN工厂 我们每个人每天用的AI助手、公司内部跑的数据分析、开发者调用的代码生成接口,都在消费Token,目前全世界消耗的TOKEN数量已经是上百万亿级别。而生产TOKEN的AI工厂,悄然排在了头部企业的资本开支计划表里。 那么,我们看看英伟达的TOKEN工厂规划(在英伟达这层应该是TOKEN工厂的工厂)都有哪些生产节点或产线(见下表),在英伟达之外可以是数据中心的升级。
可以看出:英伟达的完整元制造(Token工厂的工厂) 等同于一个自循环的AI产业园,每个节点可能对应一个或者多个公司的产品或产品线,按照咱们国内的说法,差不多就可以叫做一个AI产业超级集群。当然,可以有规模大小,根据市场和客户群体来量身定制TOKEN工厂。 三种客户,三种商业模式 那么TOKEN工厂,谁来买单?实际根据使用对象,可以分为三类: 第一类:大企业 AI工厂的第一类客户是大企业,他们不买Token,他们买专有生产线,生产专有的TOKEN。 智谱和华为联合研发的GLM-Image模型是个典型样本:从数据处理到大规模训练,全程跑在华为昇腾芯片上,完全不碰英伟达。这不是技术选型,是战略选择,大企业要的不是更便宜的Token,是数据不出门的私有工厂。智谱的路线图很清晰:把整套AI产线搬进客户内网,从算力到模型到应用全栈私有化部署。 这和当年的私有云一模一样。2008年大银行说"数据不能放在公有云上",AWS就说好那我给你建一个专属的,于是有了VPC、专有云、混合部署。今天的AI工厂同理:大企业要的是"放在自己机房里的GPT",Token计费只是其中的一小部分成本,真正的价值是安全、可控、可审计。 第二类:中小企业 第二类客户是中小企业,他们不建产线,他们租产生产线,按调用量付费,用多少Token付多少钱。 打开OpenRouter,全球开发者正在用脚投票。3月中旬的数据显示,中国大模型在OpenRouter上的周调用量已连续两周超过美国模型,前三名全是中国模型:MiniMax M2.5、阶跃星辰Step 3.5、DeepSeek V3.2,中国模型吃掉了61%的调用量。 为什么?算一笔账就清楚了,Claude Opus 4.8的输入价格是5美元/百万Token,输出25美元。MiniMax M2.5输入0.15美元、输出1.2美元,Claude的输出价是MiniMax的20.8倍。阿里Qwen3.5更激进,直接把百万Token打到0.8元(输入价格,不到0.11美元)。如下图(截止26年6月) 数据截止2026年6月 中小企业和开发者不在乎品牌,不在乎生态绑定,他们在乎的是"能不能把这个功能做出来、花多少钱"。中国模型的答案是:能,而且便宜到你不用犹豫。 但这门生意有一个致命的问题,大部分模型公司不赚钱。以国内为例,智谱(25年招股书上统计22年至25年上半年)累计亏损超过62亿元;MiniMax(2022年至2025年前三季度)累计净亏损已高达13.2亿美元。 第三类:个人用户 第三类客户是个人用户,你去便利店买一瓶可乐不会问它生产成本是多少,你打开豆包问一个问题也不会想它消耗了多少Token。但便利店老板在算,一瓶可乐进货价两块三、卖三块、一天卖一百瓶赚七十块。AI公司也在算:一个用户每月消耗100万Token、成本摊下来几毛钱,如果付费意愿跟不上,亏的是公司。 三种客户背后是三种完全不同的商业模式:大企业买的是安全溢价,中小企业买的是成本效率,个人用户买的是体验便利。同一个Token,卖给不同的人,价格可以差几十倍,成本却是一样的。 英伟达:不开矿,只卖铲子,但每一把铲子都刻着自己的名字 如果把Token工厂比作工业革命时期的纺织厂,英伟达的角色很微妙。它说"我不做AI工厂",但事实上它参与了每一个环节:CUDA是工厂的操作系统、H200/B200芯片是生产线、Omniverse是数字孪生车间、AI Foundry是一整套"交钥匙工厂"的解决方案。黄仁勋管这叫"Token经济学",真正的意思是:你不用管产线怎么搭,你只管告诉我你要什么品质的Token、要多少、预算多少,我帮你把厂建好。 整个AI产业都在往里面跑,Token的定价权不在模型公司手里,在算力供应商手里。你的模型跑在谁的芯片上、用谁的电、通过谁的云分发,谁就能在你的收入里分走最大的一块。中国模型在OpenRouter上调用量第一、收入却不一定第一,因为大部分Token是通过美国的推理服务商跑在美国的GPU上、消耗着美国的电力产出来的,赚的是辛苦钱,分的是底层的大头。 一度电怎么变成十一块钱 理解了Token工厂的客户和供应链,再看另一组数据。 南方电网和新华社在2026年算过一笔账:中国西部绿电上网价格约0.3元/度,经过智算中心的GPU处理后,一度电可以产出价值约11元的Token,增值接近20倍。 这是已经在跑的商业模式。贵州的智算中心PUE达到了1.17、内蒙古绿电占比超过80%,Token工厂正在从东部沿海向西部能源基地迁移,像当年的"东数西算"一样,只是这次算的不是存储,是Token。 微软CEO纳德拉在6月初的内部讲话中透露了一个细节:公司内部"tokenmaxxing":什么任务都用最贵的模型跑,已经变成一种风气。但企业财务系统里根本没有"Token预算"这个科目。IT采购部门管GPU、运营部门管电费、业务部门管应用,没人管"这个功能调了多少次大模型、花了多少钱"。传统工厂有财务总监、有成本中心、有KPI考核,AI工厂目前是野蛮生长,它还没有被管理起来。 这恰是下一个值得研究的话题:当Token变成一个企业的主要生产成本和产品原料,谁来管这笔糊涂账? 从大企业自建AI私有产线、到中小企业按Token付费、再到个人用AI像用水电一样自然,Token工厂这条线正在把整个AI产业从"做模型"拉进"做产能"。而不管哪一类客户,最后都会回到同一个核心问题:谁控制算力,谁控制成本,谁就能在Token这场新工业革命里活下来。 数据来源丨英伟达GTC 2026黄仁勋演讲、南方周末《Token工厂之战》(2026.3.21)、OpenRouter全球调用量排名(2026.3.16)、长江证券模型定价研报、新华社"一度电→11元"测算(2026.3.20)、智谱招股书、MiniMax招股书。 文中含AI生成图片,本文得出的一些观点属个人观点,欢迎交流。
相关内容 查看全部
-
行业AI暴露、董事
2026-06-24 11:11 -
698号文件一出,钢
2026-06-24 11:10 -
同一天、两大法、
2026-06-24 11:07 -
【检测人才招聘】
2026-06-24 11:06 -
西安市莲湖区第二
2026-06-24 11:06 -
【拟在建项目】新
2026-06-24 11:05 -
【行业篇】SMEs中
2026-06-24 11:03 -
630亿砸进一条生
2026-06-24 11:02 -
蓝鲸医疗丨医疗器
2026-06-24 11:01 -
行业资讯丨促平台
2026-06-24 11:00
