
这个系列文章,打算做一件事情,试着弄清楚一个模型在公司里到底是怎样被一群人做出来的;希望对想要从事大模型相关工作的人或者对模型训练感兴趣的读者有所帮助。
流程示意图:把本篇内容放回大模型公司的实际工作链路中理解。
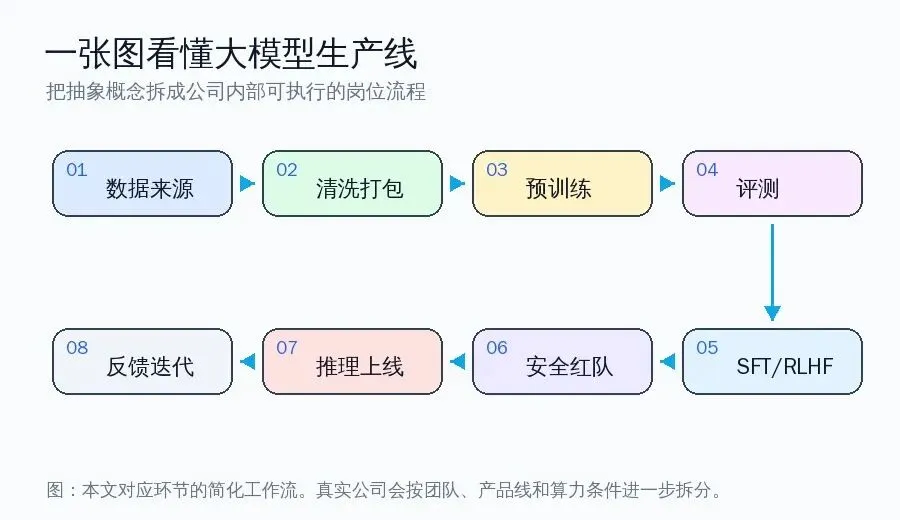
先把“大模型公司”看成一条生产线
外界看大模型公司,通常只看到几个词:数据、显卡、算法、RLHF、发布会。可是如果把镜头拉进公司内部,会发现它更像一条很长的生产线。前面有人找数据、清洗数据、制定数据比例;中间有人写训练程序、调度 GPU 集群、盯着 loss 曲线;后面有人做评测、对齐、安全测试、推理部署、API 平台和产品发布。
所以,大模型不是某个研究员一个人“炼”出来的。它是数据工程、算法研究、分布式系统、基础设施、产品、安全、运营一起协作的结果。OpenAI、DeepSeek、字节豆包、通义、Kimi 这类公司具体组织形态不同,但要完成的工序大体相似。
第一站:数据从哪里来
训练开始之前,最早进入流水线的是数据。数据可能来自网页、书籍、论文、代码、问答社区、百科、企业文档、多语种语料,也可能来自模型合成数据。这里不是简单“下载互联网”,而是有专门的数据工程和数据治理流程。
数据团队要回答几个很具体的问题:哪些来源可以用?哪些来源质量高?哪些内容有版权风险?哪些内容有隐私信息?哪些内容是垃圾网页、广告、乱码、重复转载?这些问题没有处理好,后面训练再贵也会被脏数据拖累。
第二站:数据被清洗、切分和打包
人读的是文章,模型读的是 token。网页、PDF、代码仓库、论坛帖子进入训练之前,要经历去重、去噪、语言识别、质量打分、敏感信息过滤、格式统一和 tokenizer 切分。最后,它们会变成一批批模型可读取的 token 序列。
这一步的交付物不是一句“干净数据”,而是一套数据集版本:每个版本有来源、规模、token 数、领域占比、过滤规则、质量报告和抽样样本。后面的训练团队拿到的就是这些版本化数据。
第三站:预训练开始
预训练是让模型从大量文本中学习语言、知识、代码、推理模式和世界统计规律。这里涉及研究员、算法工程师、训练工程师和平台工程师。
研究员关心模型结构、训练目标和规模策略;算法工程师把方案写成可运行程序;训练平台工程师把程序放到大规模 GPU 集群上;基础设施团队负责机器、网络、存储、驱动和监控。真正的大模型训练不是一个 Python 脚本跑到底,而是一个会持续数周甚至数月的分布式工程任务。
第四站:训练过程中要不断监控
模型训练时,团队会盯很多指标:loss 是否平稳下降,GPU 利用率是否正常,吞吐是否达标,数据加载是否卡住,网络通信是否成为瓶颈,某些节点是否掉线,checkpoint 是否能恢复。
如果训练中途 loss 突然爆炸,或者某批数据出现异常,团队要快速定位原因。可能是数据问题,可能是学习率问题,可能是混合精度溢出,也可能是集群通信故障。大模型训练贵,所以每一次中断都是真金白银。
第五站:训练完不等于能用
预训练模型完成后,通常还不能直接变成 ChatGPT 或豆包这样的助手。它可能会续写文本,但不一定知道如何听指令、如何拒绝危险请求、如何保持格式、如何做多轮对话。
所以后面还有 SFT,也就是监督微调。团队会准备问答、写作、代码、数学、工具调用、多轮对话等指令数据,让模型学会“像助手一样回答”。这些数据有人工写的,也有模型生成后人工筛选和修改的。
第六站:人类反馈和对齐
SFT 之后,模型还要经过偏好对齐。比如同一个问题生成两个答案,人类判断哪个更有帮助、更真实、更安全、更符合产品风格。这些偏好数据可以用于 RLHF、DPO 或其他对齐方法。
这里的工作不是“标注员随便点一下”。成熟团队会有标注规范、题目设计、质量抽检、专家复核、模型辅助生产和安全策略。人类反馈本质上也是一条数据生产线。
第七站:评测决定模型能不能进入下一阶段
训练、微调、对齐之后,评测团队会从很多维度测试模型:中文、英文、数学、代码、知识、长上下文、多轮对话、幻觉、安全、工具调用、行业任务。公开 benchmark 只是其中一部分,公司内部通常还有大量真实业务场景评测。
评测的交付物是报告,不是感觉。报告会列出模型相对上一版本哪里进步、哪里退步、哪些 bad case 不能接受、是否建议灰度上线。
第八站:上线服务是另一套工程
模型权重训练出来以后,还要部署成用户可调用的服务。推理团队要解决延迟、吞吐、并发、显存、KV cache、流式输出、限流、计费、监控、灰度、回滚。API 平台团队还要做鉴权、账单、SDK、文档和开发者支持。
一个模型能不能赚钱,很多时候不只看它在榜单上多高,也看它单位 token 成本多低、响应是否稳定、峰值并发能不能扛住、产品体验是否连续。
这条生产线里的岗位
如果把这些环节拆成岗位,大致会看到这些人:
- 数据工程师:负责数据抓取、清洗、存储、版本管理。
- 数据质量团队:负责抽样、标注规范、质量评估。
- 研究科学家:设计模型结构、训练目标、对齐方法。
- 算法工程师:把研究方案实现成训练代码。
- 训练平台工程师:负责分布式训练框架、任务调度、容错。
- 基础设施工程师:负责 GPU、网络、存储、驱动和监控。
- 评测工程师:负责 benchmark、内部评测集和 bad case 分析。
- 安全团队:负责红队、内容安全、合规和风险控制。
- 推理工程师:负责模型上线、加速、量化、服务稳定性。
- 产品和平台团队:负责用户场景、API、文档、计费和反馈闭环。
技术流程补充:一条主线任务会怎样被拆开
如果把一次模型版本迭代写成工程任务,通常会先落到几个具体仓库和平台里:数据仓库记录数据版本,训练代码仓库记录模型和配置,实验平台记录每次 run,评测平台记录版本对比,推理平台记录灰度流量。
一次典型版本可能这样推进:
- 数据侧产出 `dataset_v17`,包含 WARC/JSONL/Parquet 等原始或中间格式,以及 token 数、领域占比和过滤报告。
- Tokenizer 和样本侧产出 `tokenizer.model`、词表、训练 shard、索引文件和抽样检查报告。
- 训练侧提交配置文件,例如模型层数、hidden size、seq length、global batch size、学习率、并行策略和 checkpoint 间隔。
- 平台侧通过 Slurm、Kubernetes 或内部调度系统启动任务,容器镜像里固定 CUDA、PyTorch、NCCL、Megatron/DeepSpeed 版本。
- 监控侧接入 Prometheus、Grafana、DCGM、训练日志和实验追踪工具,持续看 loss、tokens/sec、GPU 利用率、网络通信和故障节点。
- 评测侧自动触发 benchmark 和内部测试集,生成版本对比表。
- 推理侧用 vLLM、TensorRT-LLM 或内部引擎做延迟、吞吐和成本测试,再进入灰度。
所以内部工作流里最重要的不是“某个概念”,而是每个环节都有可追踪的输入、配置、产物和验收指标。
