
有一个问题在物流行业今年被反复问起:应该先上大模型,还是先补数据治理?
国家数据局在6月8日发布的《关于推进行业高质量数据集建设行动的实施方案》里,给了一个清晰的顺序。方案指出,行业高质量数据集是"推动人工智能+赋能千行百业、实现产业落地的基础性、关键性资源",并将整个行动体系概括为一个"数据飞轮":场景牵引数据、数据驱动模型、模型赋能应用、应用创造价值。
注意这个顺序:场景在最前,数据第二,模型第三,应用收尾。大模型不是起点,是中间环节。
6月11日,交通运输部科技司司长徐文强在国家数据局新闻发布会上进一步说清楚了物流行业的现状:"行业大模型训练中,数据治理工具缺乏、高质量语料不足,是核心瓶颈。"他同时宣布,交通运输部今年专门在"数据要素×"大赛里设置了"人工智能大模型与高质量数据集建设"赛题,目的是破解这个卡点。
对于准备在2026年推进数字化建设的物流企业来说,政策的顺序已经说得很直白了。现在的问题是:具体怎么做。
政策给的逻辑:先治理,再打通,再训练,再应用
方案提出的六个专项行动,名称看起来有些学术,但对应到物流企业的实际工作,每一个都有具体的落地内容。
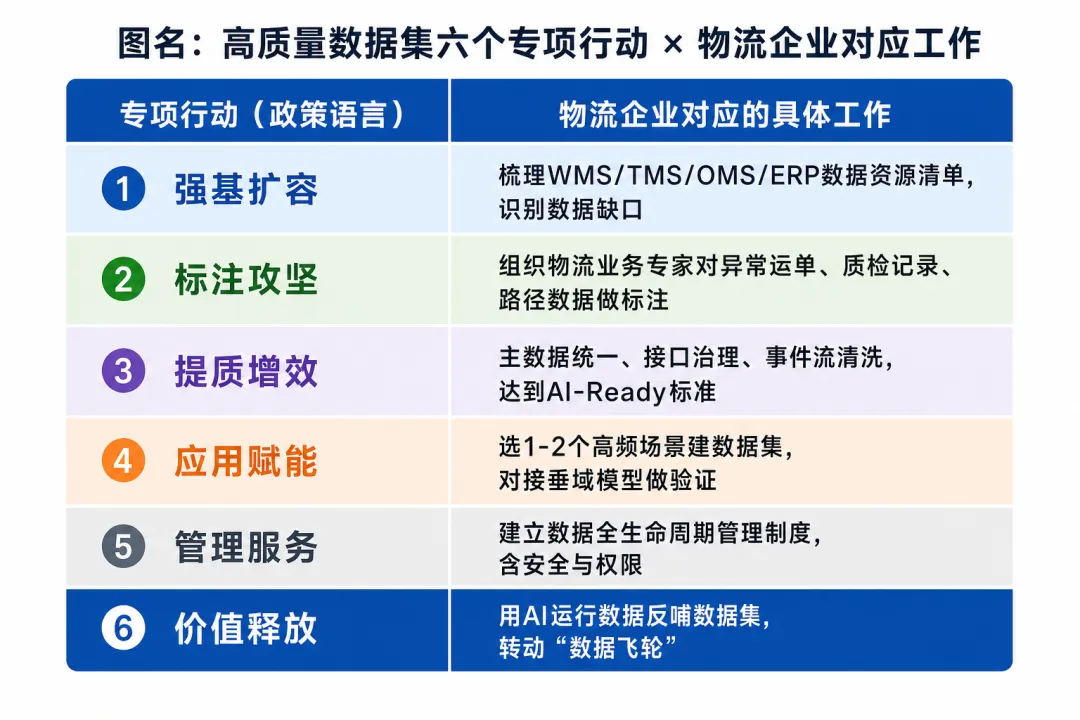
强基扩容行动,对应的是盘底数。方案要求"梳理行业数据资源底数和应用场景,建立数据资源清单和数据集需求清单"。对物流企业来说,那就要回答一个基本问题:现在有哪些系统、每个系统沉淀了什么数据、哪些数据可以用来训练模型、哪些数据根本没有被采集到?WMS里的库存流水、TMS里的运单轨迹、OMS里的订单履约记录——这些数据的质量和覆盖度,决定了你能训练什么模型,也决定了你能做什么场景。
标注攻坚行动,对应的是让行业专家给数据打标签。方案强调"建立行业专家认证机制,推动专家深度参与指令微调、强化学习等阶段所需的专业知识标注"。这件事对物流企业特别重要——运单异常判断、路径合理性评估、货物损坏归因,这类判断需要真正懂物流的人来标注,不是通用的众包平台能替代的。没有高质量标注,训练出来的模型在行业场景里表现会很差。
提质增效行动,对应的是数据清洗和接口治理。方案要求建设"满足AI-Ready(可直接用于训练)"的高质量数据集。很多物流企业的数据现状是:WMS、TMS、ERP各自为政,主数据不统一(同一个仓库在三个系统里有三种叫法),事件流记录不完整,历史数据积累了但格式混乱、缺失严重。这类数据在送进模型之前,需要做大量清洗和规范化工作,这不是AI的任务,是数据工程的任务。
应用赋能行动,对应的是从小切口场景开始建设数据飞轮。国家数据局新闻发言人在发布会上专门强调:"优秀的项目往往从特定场景应用着手,真正解决行业发展的各类小堵点小卡点,而不只是停留在'宏大叙事'和'PPT画饼'上。"物流行业有一个典型的"宏大叙事"陷阱——上来就要建"物流大模型",覆盖运营全流程。但如果没有对应的高质量数据集,这个大模型要么训练出来没用,要么根本训练不了。
价值释放行动,是整个闭环的最后一步:让AI应用产生的动态交互数据,反过来优化数据集,驱动模型能力持续提升。方案把这个描述为"数据飞轮"的完整转动。
交通运输赛道为什么把"全域物流供应链数据融合"单独列出来
这次"数据要素×"大赛交通运输赛道的题目设置,值得物流企业仔细看一遍。
徐文强介绍的几个核心赛题里,有一条专门针对物流:"全域物流供应链数据融合"——推动多式联运"一单制"全程可视化,让"物畅其流"加速落地。
这个赛题的存在本身就说明一件事:数据打通,在行业层面至今仍然是没解决的问题。发货人、承运人、仓储方、海关、港口之间的数据流转,在大多数场景里还是靠人工传递,而不是系统自动共享。一票货物从出仓到到港,可能经过五个系统的手工录入,每经过一次就丢失一些精度。
"全域物流供应链数据融合"是2026年的行业赛题,不是已经解决的问题。物流企业在推进数字化的时候,要对这个现状有清醒认知:打通比上模型更紧迫,不打通就没有可用的数据,没有可用的数据就没有可训练的模型。
与此同时,赛道还设置了"人工智能大模型与高质量数据集建设"赛题,明确任务是"破解行业大模型训练中数据治理工具缺乏、高质量语料不足等瓶颈"。两个赛题并列,说明政策层的判断是:数据融合和数据集建设,是大模型能否在物流行业真正落地的前提条件,而不是大模型落地之后可以慢慢解决的问题。
交通运输部已经走在前面一步:2025年综合交通运输数据资源库汇集高价值数据近500项,对接国家数据共享交换平台,累计汇聚数据29亿条,存储容量达76TB,已支撑35个业务信息化系统高效运行。这是部委层面的数字底座建设成果。物流企业如果想接入这套数据基础设施,自身的数据治理水平也需要达到一定标准。
物流企业的2026年数字化建设顺序表
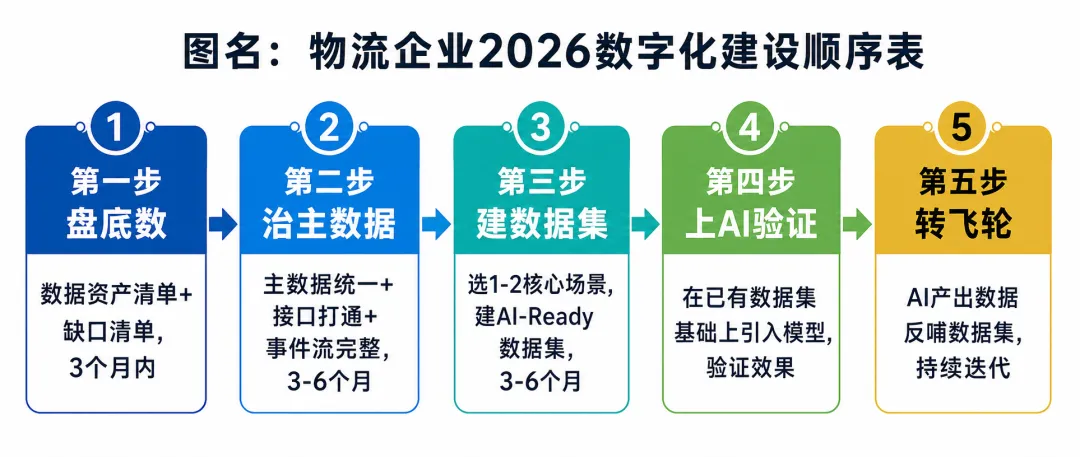
基于上述政策逻辑,我们可以按照"用有限资源做最有价值的事"逻辑排出来的优先级给出一个可以操作的建设顺序
第一步:盘清数据家底
不是做大型数据规划,而是做一张清单:
现有哪些业务系统(WMS、TMS、OMS、ERP、BI等),每个系统的数据覆盖范围是什么; 哪些核心业务场景的数据是完整的、可用的;哪些是碎片化的、缺失的; 数据的主数据标准是否统一(客户编码、货位编码、运单号、SKU编码是否全公司一套)。
这一步做完,你会得到两张清单:数据资产清单,和数据缺口清单。后者往往比前者更重要。
第二步:治理主数据和接口,打通事件流
数字化投入最容易浪费在"系统上了,数据不通"上。在考虑引入任何AI能力之前,需要先解决几个基础问题:
主数据是否统一?不统一的主数据会导致跨系统数据无法关联; WMS、TMS、OMS之间是否有完整的接口,能实时同步关键事件(出库、交接、签收、异常)? 事件流记录是否完整?只有完整的事件流,才能训练出对异常有感知能力的模型。
这一步不是技术问题,是管理问题——需要业务部门和IT部门共同定义标准,并且推动各个系统的数据按标准输出。
第三步:选1-2个核心场景,建设高质量数据集
方案的原则是"急用先行、应用验证"——不是先建数据集再找场景,而是先定场景、再围绕场景建数据集。
物流行业优先级较高的几个候选场景:
运单异常识别:哪些运单在哪个环节容易出问题?需要完整的运单轨迹数据+异常标注; 库存预测优化:哪些SKU的备货量容易偏高或偏低?需要历史销售数据+入库出库流水+外部需求信号; 路径时效预测:某条干线在什么情况下会延误?需要历史运单+天气+车辆状态的融合数据集。
选定场景之后,按照方案要求,建设满足"AI-Ready"标准的数据集:格式统一、标注准确、来源可追溯,经过业务专家的验证。
第四步:在已有数据集的场景上引入AI,验证效果(持续迭代)
这一步才是引入大模型或垂域小模型的时机。在数据集质量有保障的前提下,模型的选型反而相对次要——通用大模型微调、行业垂域模型、自建小模型,都可以在已有数据集上快速验证效果。
没有数据集基础就上大模型,最常见的结果是:模型跑起来了,但对业务场景完全不准,最终变成一个演示型工具,没有实际价值。
第五步:让AI产生的数据反哺数据集,转动飞轮
AI在真实场景里运行之后,会产生新的动态交互数据——模型做了什么决策、结果如何、用户是否接受。这些数据本身就是高质量的训练素材,可以持续优化数据集,让模型越用越准。这就是方案描述的"数据飞轮"机制,也是数字化建设从"项目投入"转向"持续运营"的关键节点。
这轮政策的核心判断,已经由国家数据局说得很直白:"优秀的项目往往在数据治理方面下了很大功夫,很多形成了高质量数据集,成为了人工智能发展的'燃料'。"
对大多数物流企业来说,2026年的数字化重心,不应该是采购什么AI产品,而是把已有的数据资产盘清楚、治理好、打通连接,让它真正具备可以被AI使用的质量。这件事做扎实了,后面的模型和应用才有基础;跳过这件事,后面的钱大概率打了水漂。
数字化建设不缺宣传,缺的是顺序。先把数据的账算清楚,再谈大模型。
