
去年我花了三个月研究AI工作流,走了不少弯路。
最大的坑是:把时间都花在了"选模型"上,而不是"建管道"上。
现在我用3个工具搭了一套完整的流水线——每天自动产出视频,数周没碰过剪辑软件。这套架构拆开来,其实就四层,每一层都能单独用,按你自己的节奏来。
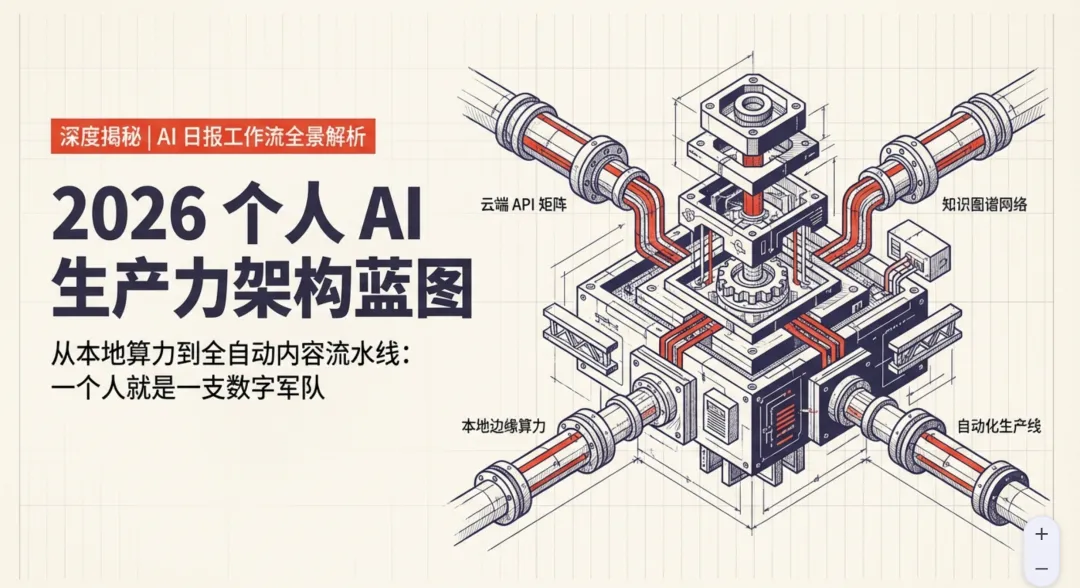
四层架构:从云端API到自动发布,一个人就是一支团队
① 第一层:免费薅遍13家API,先别花一分钱
很多人第一步就被"付费"劝退了。
实际情况是:GPT-4o、Gemini-1.5、Claude、DeepSeek、Qwen2.5,这13家都有免费的开发者额度,够你把整套架构跑通,完全不用付费。
操作就三步:去各家官方开发者平台注册,拿API Key,跑下面这几行代码:
import openaiclient = openai.OpenAI(api_key='your_key', base_url='...')response = client.chat.completions.create(model='gpt-4o', messages=[...])print(response.choices[0].message.content)
直接调API比网页端快30%,Prompt可以精确控制,不受各种过滤限制。第一次跑通的时候,确实有点上头。
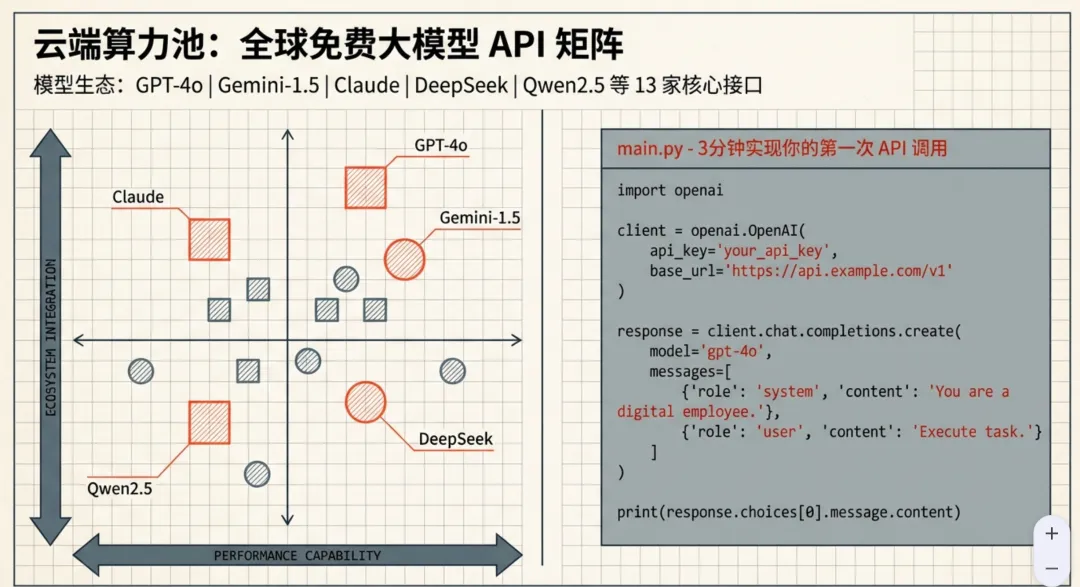
13家模型各有侧重——GPT-4o性能强、DeepSeek性价比高、Qwen2.5中文最稳
② 第二层:AI写代码越写越乱?你少做了这一步
我踩过这个坑:让AI帮我写一套自动化脚本,第一版还行,改了几轮之后逻辑开始乱,最后推倒重来。
根源是没有规范文档(Spec)。AI不是你肚子里的蛔虫,你不说清楚边界,它就随机发挥。
现在用的是GSD工作流,三步:
? Goal:在Obsidian里把目标写清楚 ? Spec:定义这个程序做什么、不做什么、边界在哪 ⚡ Do:让OpenClaw读取Spec,严格执行,不瞎猜意图
听起来多了步骤,但实测省了至少80%的返工时间。代码越改越烂的问题,根本上是信息传递的问题。
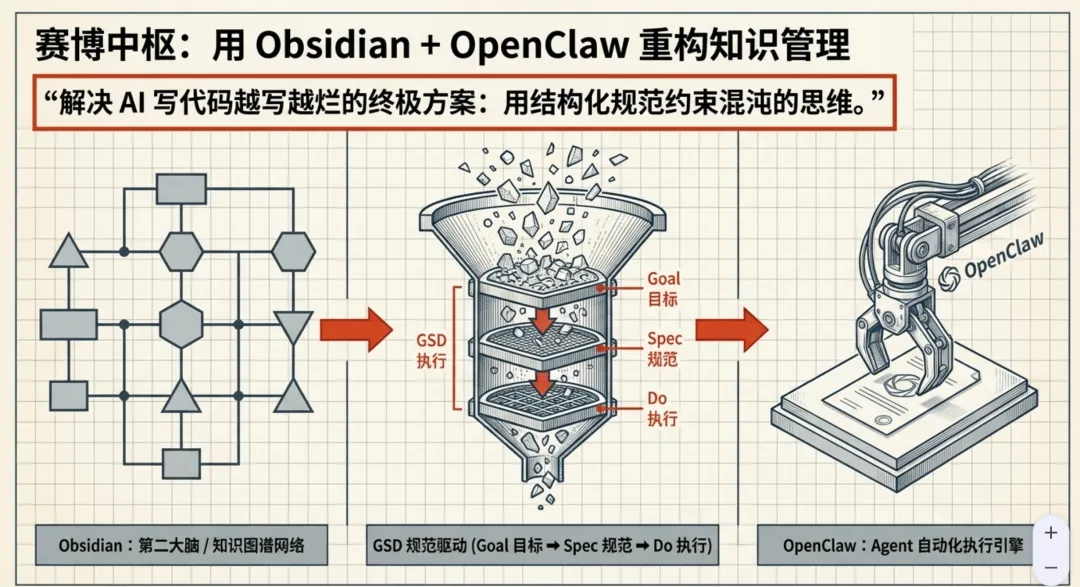
Obsidian建知识图谱 → GSD规范驱动 → OpenClaw自动执行,三件套缺一不可
③ 第三层(选修):P104矿卡跑本地大模型,数据不上云
这层不是必须的。但如果你有隐私需求,或者想零成本长期运行,这是唯一的选择。
方案很简单:闲鱼500-800元收一块P104矿卡,装Linux + NVIDIA驱动 + Ollama,本地就能跑DeepSeek、Llama系列。
P104是以太坊矿机拆下来的显卡,没有视频输出接口,但显存够大,跑7B-13B模型完全没问题。垃圾佬的终极浪漫——把数据主权握在自己手里。
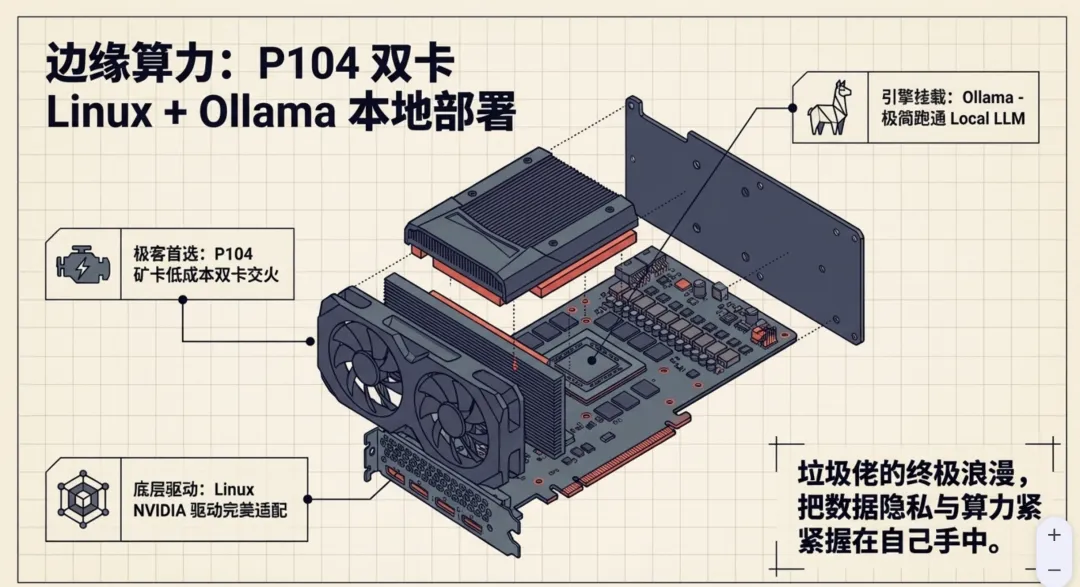
P104双卡 + Linux NVIDIA驱动 + Ollama,全套成本控制在2000元内
④ 第四层:真正的"AI员工"——自己剪辑、自己发布
前三层都是基础设施,这层才是真正出活的地方。
整条流水线是这样的:
? AI嗅探 → 自动抓取最新信息源 ⬇️ ✍️ LLM生成 → 输出Markdown稿件 ⬇️ ? md2video + IndexTTS2 → 自动渲染画面和配音 ⬇️ ? 定时发布 → B站/视频号/抖音
我自己跑了大概三周,中途没碰过剪辑软件。唯一需要人工干预的地方:某些信息源需要手动更新订阅地址,其他全自动。
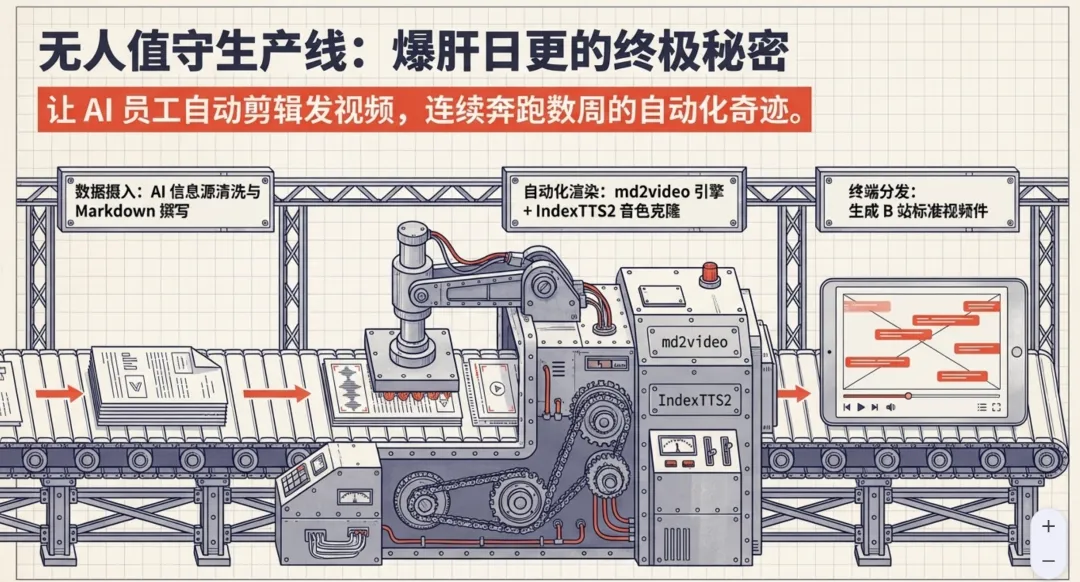
数据摄入→自动渲染→终端分发,全链路无人值守,爆肝日更的底层逻辑
从哪一层开始都行,不用一次全上
四层架构不需要同时搭,按你的节奏来:

? 通信官:注册13家免费API,建底层模型池 ? 研究员:部署Obsidian + GSD工作流,解决AI乱写代码的问题 ? 工程师:淘块旧显卡,用Ollama在本地点亮专属大模型 ? 剪辑师:跑通md2video脚本,开启全自动自媒体生产线
AI IN ALL — 时代正在奖励那些敢折腾的人
你现在用AI最多的场景是什么?还在对话框聊天,还是已经接上了自动化管道?评论区说说,看看大家现在都走到哪一步了。
数据来源:各大模型官方开发者文档 / 开源社区整理
