





2511.20633
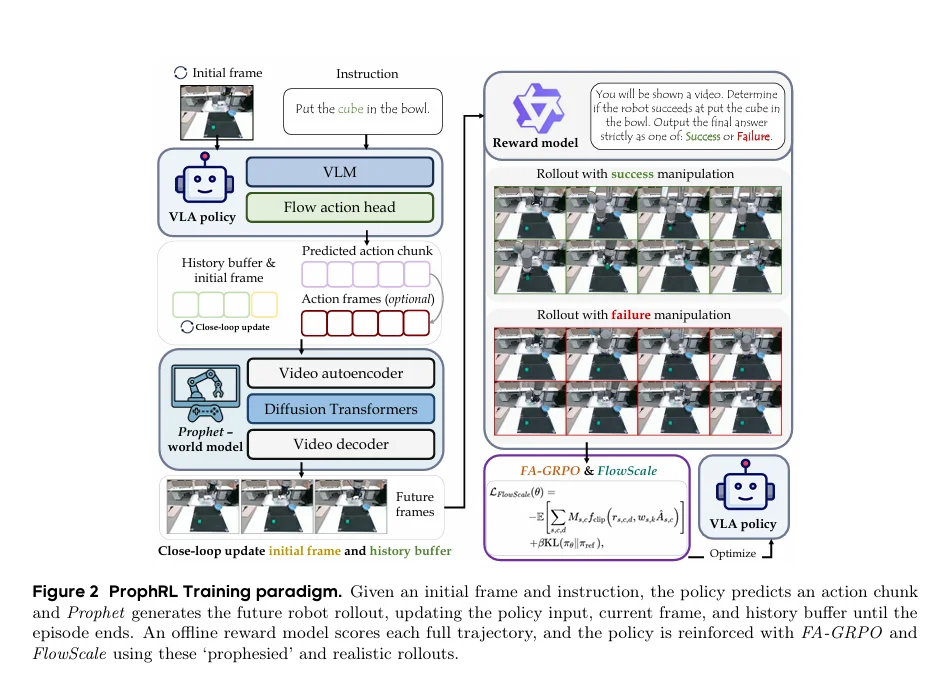
Prophet是一种经过大规模异构机器人数据预训练的动作到视频机器人驱动模型,核心在于学习可重用的动作-结果动力学,从而充当一个可立即用于轨迹生成的世界模型或模拟器。它能快速适应新环境和物体,实现高效的少样本适应。
Prophet世界模型的技术细节:
基于潜在视频扩散: Prophet模型构建在latent video diffusion pipeline之上,利用DiT)架构来预测视频帧序列。
双层动作条件输入: 为确保生成的视频精确反映机器人操作,模型采用双层机制来整合动作信息:
全局动作流嵌入: 机器人低级控制命令被表示为7维向量,包括三维平移变化、三维欧拉角旋转变化和抓手开关比例。这些动作被组织成动作块,展平后通过多层感知机(MLP)转换为全局标量嵌入,并添加到DiT的时间步嵌入中,作为高层次的动作指引。
可选动作帧潜在嵌入: 为了更精细地编码动作的几何信息,Prophet将末端执行器的动作投影到图像平面,并根据深度信息和抓取状态进行渲染,生成几何感知的动作帧。这些动作帧被编码为潜在嵌入,作为额外的条件添加到DiT块中。
长程时间连续性保证: 传统的视频生成模型难以保持长时程轨迹的稳定性和物理一致性。Prophet通过引入历史感知机制(基于FramePack技术)来解决:
模型维护一个低分辨率的过去潜在帧内存缓冲区。
在DiT处理当前帧时,将历史缓冲区中的信息通过额外的键值向量形式馈入,为模型提供长程的时间上下文。
视频生成采用自回归分块方式,将上一个生成的视频片段的最后一帧作为下一个片段的起始帧,新生成的片段压缩后添加到历史缓冲区,持续维护时间上的连续性,从而确保长期操作轨迹的几何和接触演化稳定可靠。
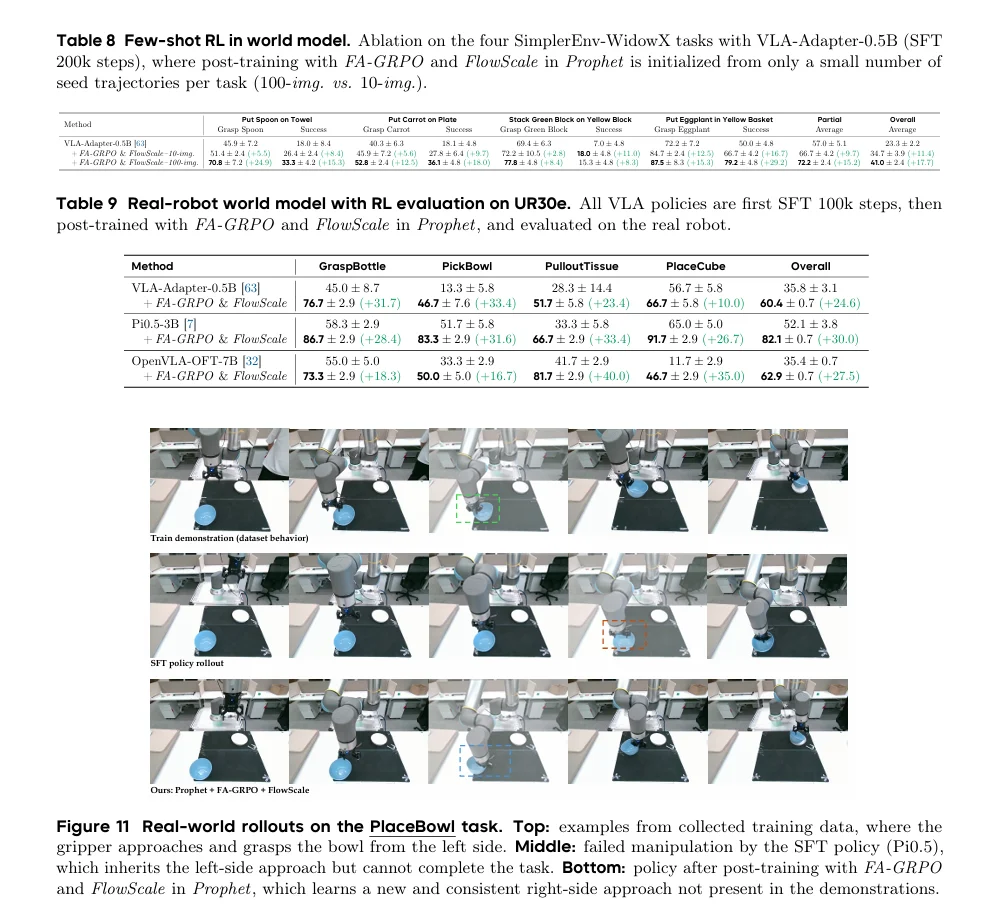
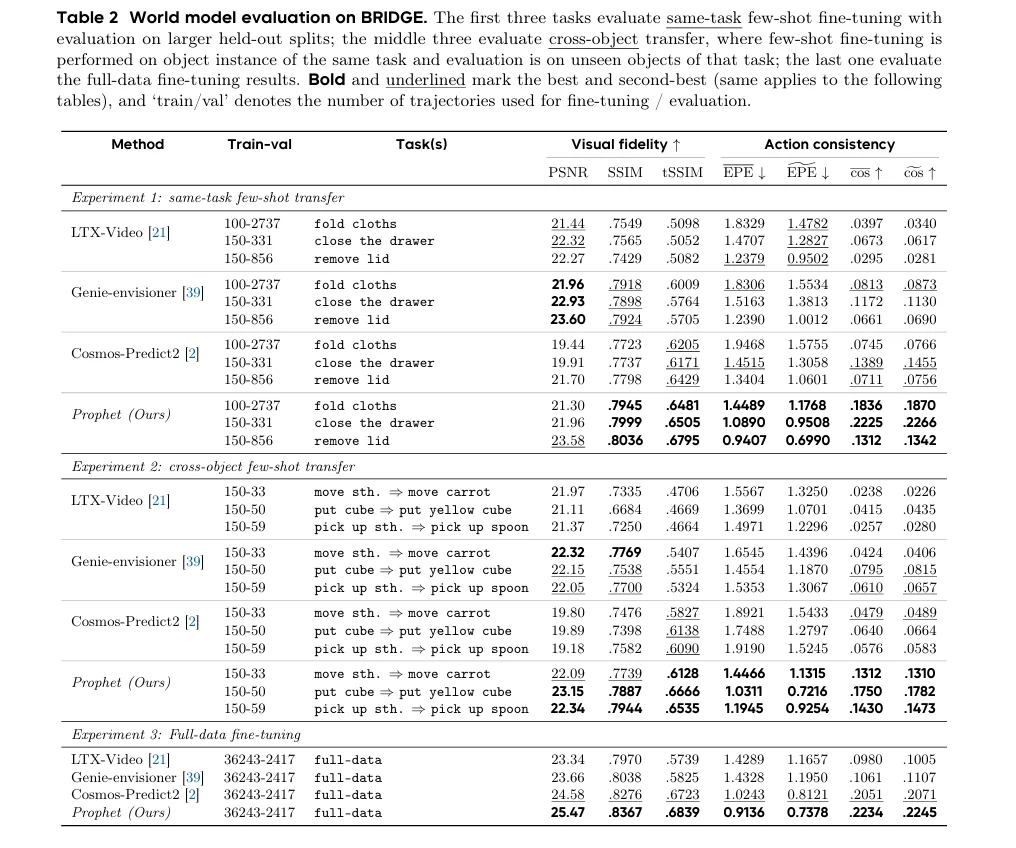
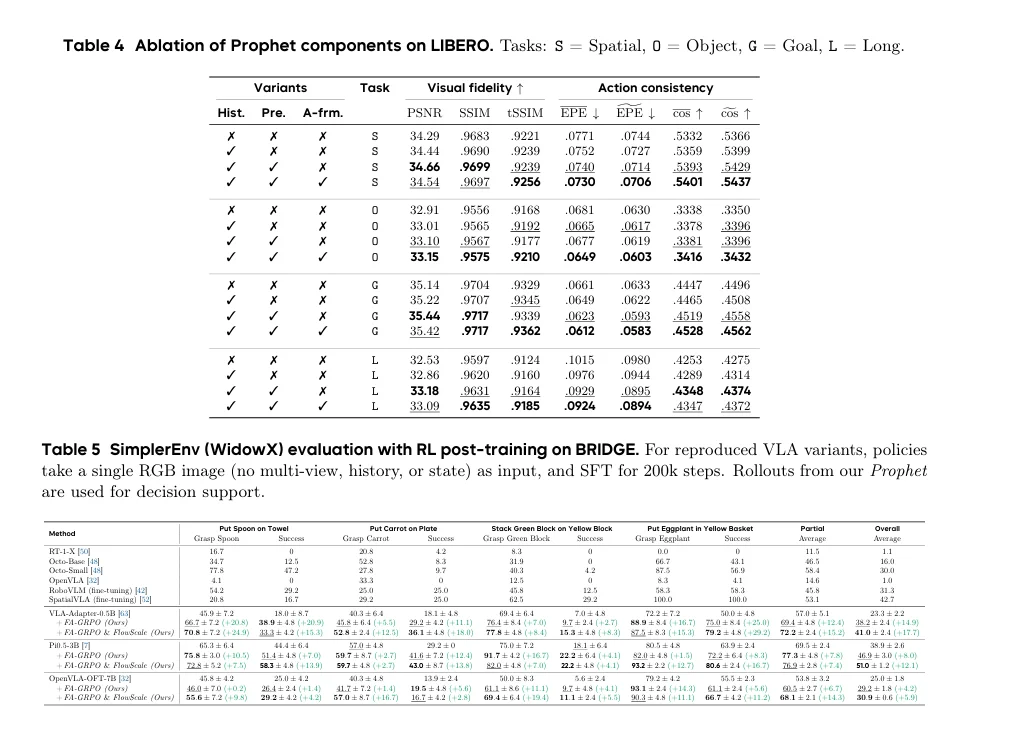
动作保真度评估: 为了验证Prophet生成的rollout是否准确执行了输入的动作,模型引入了光流引导评估协议。该协议通过比较真实视频和Prophet生成的rollout之间的运动场来量化动作执行的正确性。关键指标聚焦于端点误差(EPE)和流方向余弦相似度,能有效捕捉控制相关的运动幅度与方向,避免了传统视频质量指标的模糊性,确保Prophet是一个“rollout-ready”的高保真模拟器。
Prophet是一种经过大规模异构机器人数据预训练的动作到视频机器人驱动模型,核心在于学习可重用的动作-结果动力学,从而充当一个可立即用于轨迹生成的世界模型或模拟器。它能快速适应新环境和物体,实现高效的少样本适应。
Prophet世界模型的技术细节:
基于潜在视频扩散: Prophet模型构建在latent video diffusion pipeline之上,利用DiT)架构来预测视频帧序列。
双层动作条件输入: 为确保生成的视频精确反映机器人操作,模型采用双层机制来整合动作信息:
全局动作流嵌入: 机器人低级控制命令被表示为7维向量,包括三维平移变化、三维欧拉角旋转变化和抓手开关比例。这些动作被组织成动作块,展平后通过多层感知机(MLP)转换为全局标量嵌入,并添加到DiT的时间步嵌入中,作为高层次的动作指引。
可选动作帧潜在嵌入: 为了更精细地编码动作的几何信息,Prophet将末端执行器的动作投影到图像平面,并根据深度信息和抓取状态进行渲染,生成几何感知的动作帧。这些动作帧被编码为潜在嵌入,作为额外的条件添加到DiT块中。
长程时间连续性保证: 传统的视频生成模型难以保持长时程轨迹的稳定性和物理一致性。Prophet通过引入历史感知机制(基于FramePack技术)来解决:
模型维护一个低分辨率的过去潜在帧内存缓冲区。
在DiT处理当前帧时,将历史缓冲区中的信息通过额外的键值向量形式馈入,为模型提供长程的时间上下文。
视频生成采用自回归分块方式,将上一个生成的视频片段的最后一帧作为下一个片段的起始帧,新生成的片段压缩后添加到历史缓冲区,持续维护时间上的连续性,从而确保长期操作轨迹的几何和接触演化稳定可靠。
动作保真度评估: 为了验证Prophet生成的rollout是否准确执行了输入的动作,模型引入了光流引导评估协议。该协议通过比较真实视频和Prophet生成的rollout之间的运动场来量化动作执行的正确性。关键指标聚焦于端点误差(EPE)和流方向余弦相似度,能有效捕捉控制相关的运动幅度与方向,避免了传统视频质量指标的模糊性,确保Prophet是一个“rollout-ready”的高保真模拟器。
