
在人工智能领域,RAG 是 Retrieval-Augmented Generation 的缩写,中文译为检索增强生成。它是一种将信息检索与大语言模型生成能力相结合的技术框架。
其核心思想很直观:当大模型需要回答一个问题时,它不会仅凭自身已记忆的知识来回答,而是会先从一个外部的知识库(如公司文档、数据库等)中去查找相关信息,然后结合查找到的信息来生成答案。这个过程类似于让学生参加“开卷考试”,先翻阅资料找到相关依据,再组织答案,这能有效减少凭空杜撰。
大多数人认为 RAG 的工作原理是这样的:索引一个文档→检索该文档。
但索引≠检索。
你索引的内容不必是你输入到LLM中的内容。
一旦你理解了这一点,你就可以构建真正有效的 RAG 系统。
以下是区分优秀 RAG 和卓越 RAG 的 4 种索引策略:
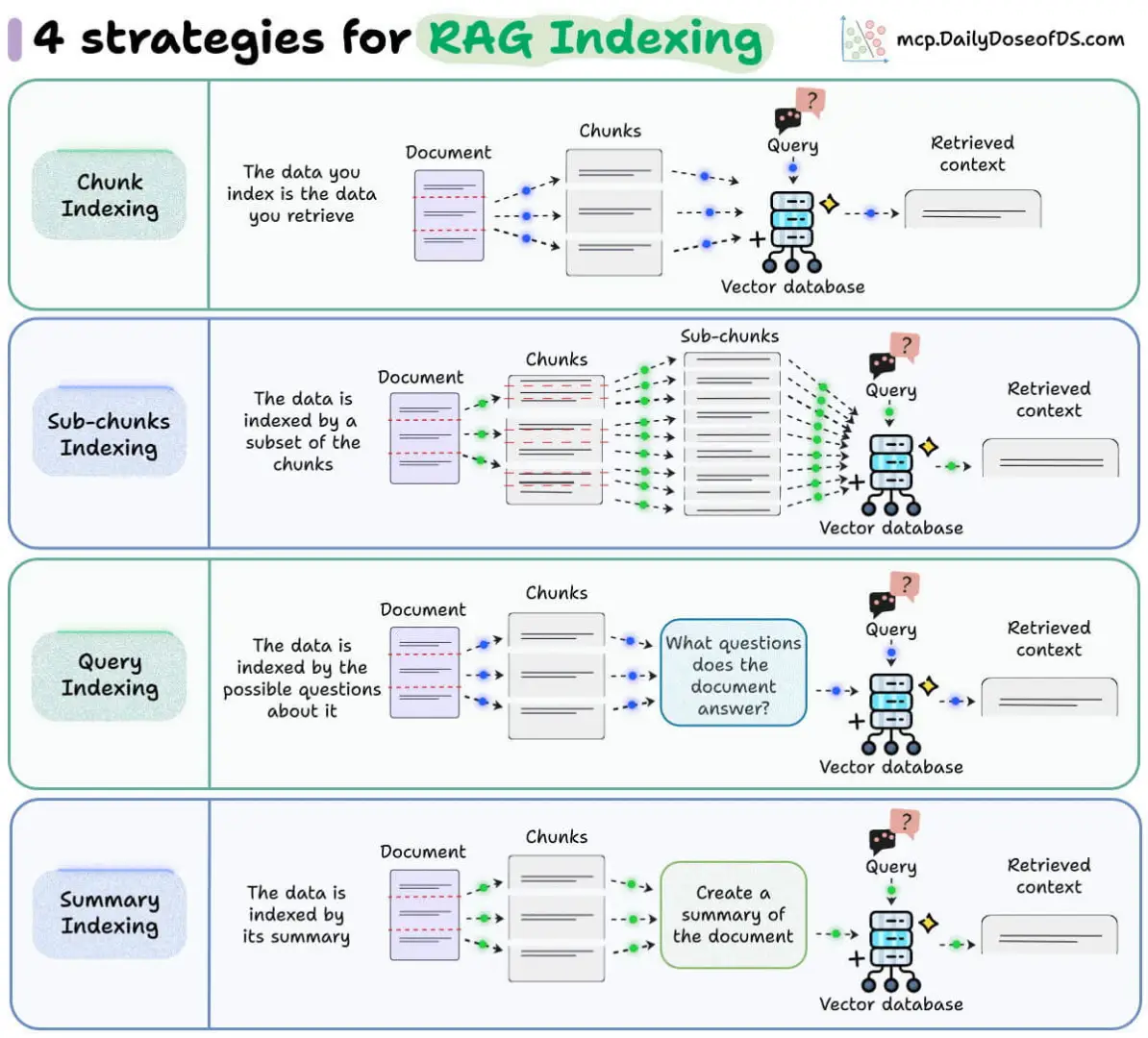
1)块索引
↳这是标准方法。将文档分割成块,进行嵌入,存储在向量数据库中,并检索最接近的匹配项。
↳简单有效,但大块或嘈杂的块会影响精度。
2)子块索引
↳将数据块分成更小的子数据块以便进行索引,但要检索完整的数据块以获取上下文。
↳当单个章节涵盖多个概念时,这种方法非常有效。它既能提高查询匹配度,又不会丢失法学硕士(LLM)所需的上下文信息。
3)查询索引
↳与其索引原始文本,不如生成该文本块可以回答的假设性问题。然后对这些问题进行索引。
↳用户查询自然比原始文档文本更能贴近问题本身。这缩小了用户提出的问题与您存储的内容之间的语义差距。
↳非常适合质量保证系统。
4)摘要索引
↳使用 LLM 对每个数据块进行概括。为概括内容建立索引,然后检索完整数据块。
↳对于像 CSV 和表格这样密集、结构化的数据,这种方法非常有效,而原始文本嵌入则效果不佳。
结论是:
你不需要检索到与索引内容完全相同的内容。将索引策略与数据相匹配,你的 RAG 系统性能将显著提升。
#AI人工智能 #开发者选项 #深度学习 #大模型 #前端 #算法 #产品经理 #后端开发 #深度学习与神经网络 #用户体验设计
其核心思想很直观:当大模型需要回答一个问题时,它不会仅凭自身已记忆的知识来回答,而是会先从一个外部的知识库(如公司文档、数据库等)中去查找相关信息,然后结合查找到的信息来生成答案。这个过程类似于让学生参加“开卷考试”,先翻阅资料找到相关依据,再组织答案,这能有效减少凭空杜撰。
大多数人认为 RAG 的工作原理是这样的:索引一个文档→检索该文档。
但索引≠检索。
你索引的内容不必是你输入到LLM中的内容。
一旦你理解了这一点,你就可以构建真正有效的 RAG 系统。
以下是区分优秀 RAG 和卓越 RAG 的 4 种索引策略:
1)块索引
↳这是标准方法。将文档分割成块,进行嵌入,存储在向量数据库中,并检索最接近的匹配项。
↳简单有效,但大块或嘈杂的块会影响精度。
2)子块索引
↳将数据块分成更小的子数据块以便进行索引,但要检索完整的数据块以获取上下文。
↳当单个章节涵盖多个概念时,这种方法非常有效。它既能提高查询匹配度,又不会丢失法学硕士(LLM)所需的上下文信息。
3)查询索引
↳与其索引原始文本,不如生成该文本块可以回答的假设性问题。然后对这些问题进行索引。
↳用户查询自然比原始文档文本更能贴近问题本身。这缩小了用户提出的问题与您存储的内容之间的语义差距。
↳非常适合质量保证系统。
4)摘要索引
↳使用 LLM 对每个数据块进行概括。为概括内容建立索引,然后检索完整数据块。
↳对于像 CSV 和表格这样密集、结构化的数据,这种方法非常有效,而原始文本嵌入则效果不佳。
结论是:
你不需要检索到与索引内容完全相同的内容。将索引策略与数据相匹配,你的 RAG 系统性能将显著提升。
#AI人工智能 #开发者选项 #深度学习 #大模型 #前端 #算法 #产品经理 #后端开发 #深度学习与神经网络 #用户体验设计
