




Agentic RL(智能体强化学习),旨在通过强化学习让大模型不再只是回答者,而是能自主规划、调用工具(如搜索、代码执行)、并基于结果进行反思的智能体。其核心是掌握“何时做、做什么、如何修正”的决策能力。
下面是该领域的一些关键进展,希望能为大家提供启发:
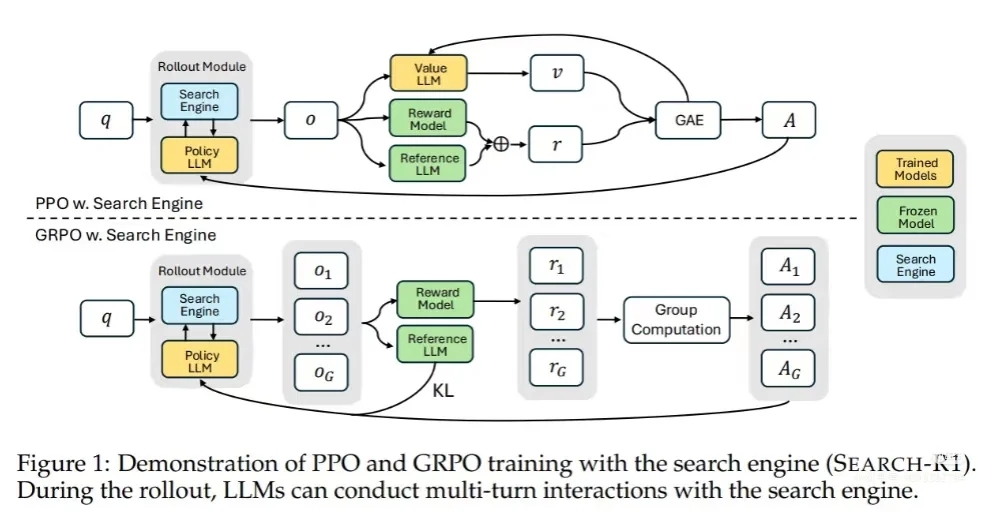
Search-R1: 训练模型学会“边搜边想”
开创了将多轮检索与推理融合进模型的范式。通过引入 <search> , <think> 等结构化标签,让LLM自主控制搜索时机,并利用“检索令牌掩码”等技术有效过滤噪声,专注于学习决策过程。
ToRL: 工具使用的扩展与效率控制
将工具范围从搜索扩展到代码执行器等,建立了“生成-暂停执行-结果注入”的交互机制。为解决工具调用带来的效率问题,引入了调用频率上限等控制策略,确保训练流程高效稳定。
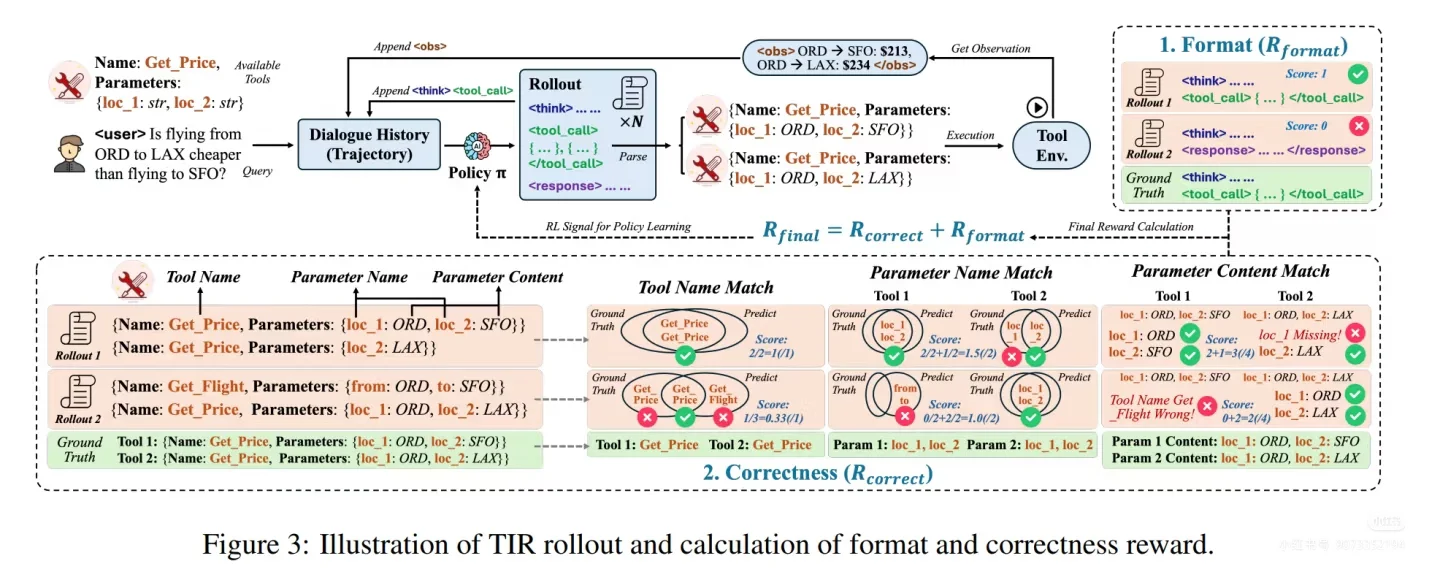
ToolRL: 奖励设计的深化
提出在工具学习场景中,细粒度的过程奖励比稀疏的结果奖励更有效。其奖励函数分解为工具名称、参数、取值匹配等多个维度,证明了这种设计能带来更稳定、高效的学习效果。
GiGPO: 破解信用分配难题
针对强化学习中长期存在的奖励归属模糊问题,提出了“组内组”策略优化。通过在整体轨迹和关键决策点两个层面计算优势,无需额外网络即可实现更精准的信用分配,提升训练效率。
Agent RL Scaling Law: 智能体能力的缩放定律
研究发现,随着训练进行,模型自发使用工具的频率、响应长度和任务准确率会同步提升,揭示了智能体性能随训练规模增长的正相关定律,为投入评估提供了重要参考。
总结来看,Agentic RL 的发展脉络清晰:从单一工具调用走向多元工具协同,从依赖结果奖励迈向关注细粒度过程奖励,并从粗放训练演进到信用分配与训练稳定性的深度优化。这正推动大模型向真正的“思考者”和“行动者”演进。
#agent #大模型 #计算机视觉 #人工智能发展 #深度学习 #科研 #
下面是该领域的一些关键进展,希望能为大家提供启发:
Search-R1: 训练模型学会“边搜边想”
开创了将多轮检索与推理融合进模型的范式。通过引入 <search> , <think> 等结构化标签,让LLM自主控制搜索时机,并利用“检索令牌掩码”等技术有效过滤噪声,专注于学习决策过程。
ToRL: 工具使用的扩展与效率控制
将工具范围从搜索扩展到代码执行器等,建立了“生成-暂停执行-结果注入”的交互机制。为解决工具调用带来的效率问题,引入了调用频率上限等控制策略,确保训练流程高效稳定。
ToolRL: 奖励设计的深化
提出在工具学习场景中,细粒度的过程奖励比稀疏的结果奖励更有效。其奖励函数分解为工具名称、参数、取值匹配等多个维度,证明了这种设计能带来更稳定、高效的学习效果。
GiGPO: 破解信用分配难题
针对强化学习中长期存在的奖励归属模糊问题,提出了“组内组”策略优化。通过在整体轨迹和关键决策点两个层面计算优势,无需额外网络即可实现更精准的信用分配,提升训练效率。
Agent RL Scaling Law: 智能体能力的缩放定律
研究发现,随着训练进行,模型自发使用工具的频率、响应长度和任务准确率会同步提升,揭示了智能体性能随训练规模增长的正相关定律,为投入评估提供了重要参考。
总结来看,Agentic RL 的发展脉络清晰:从单一工具调用走向多元工具协同,从依赖结果奖励迈向关注细粒度过程奖励,并从粗放训练演进到信用分配与训练稳定性的深度优化。这正推动大模型向真正的“思考者”和“行动者”演进。
#agent #大模型 #计算机视觉 #人工智能发展 #深度学习 #科研 #
