




? 翰林侍读在此!给陛下奉上今日AI领域的论文速报!
? 右滑查看士子奏报和论文重要图表——
?? 关注微臣,每天批阅更多奏章!
? 论文标题:Non-myopic Matching and Rebalancing in Large-Scale On-Demand Ride-Pooling Systems Using Simulation-Informed Reinforcement Learning
? Arxiv ID:2510.25796v1
? 关键词:ride-pooling, reinforcement learning, simulation, non-myopic decision-making, cost savings
? 太长不看版:该研究提出了一种基于模拟增强学习的拼车调度策略,有效提高了服务效率并降低运营成本。
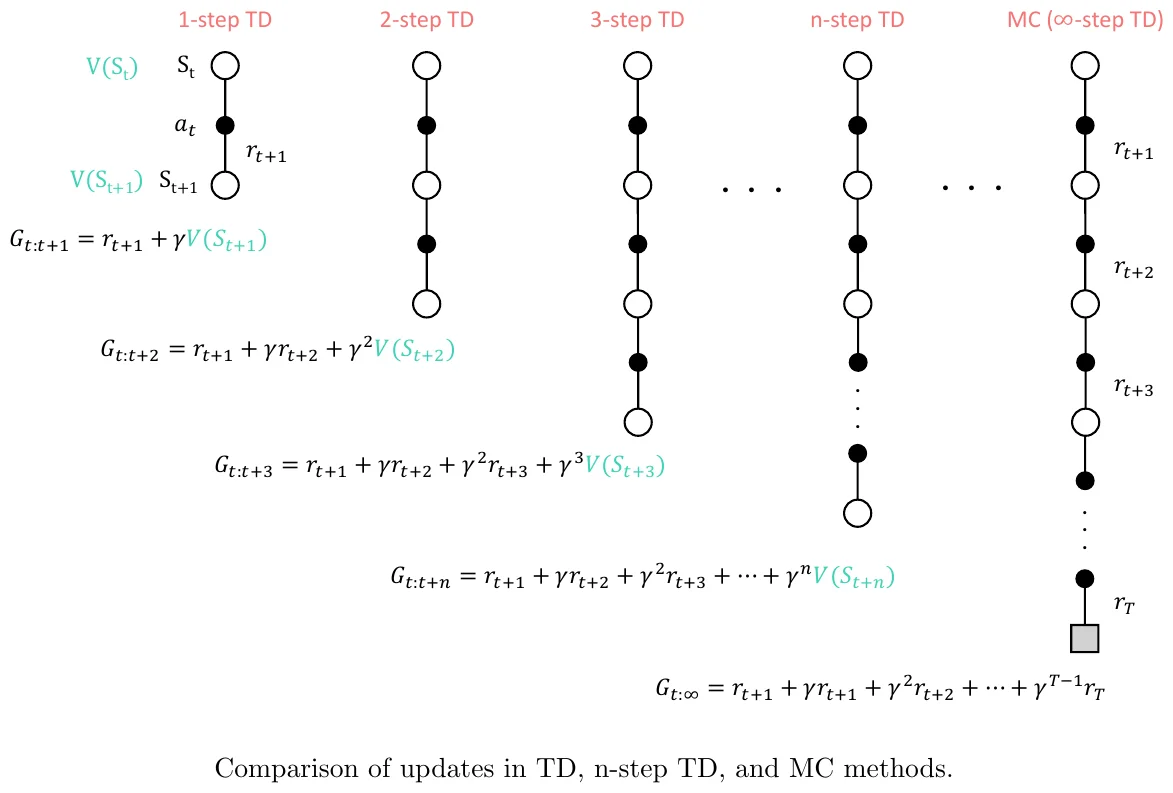
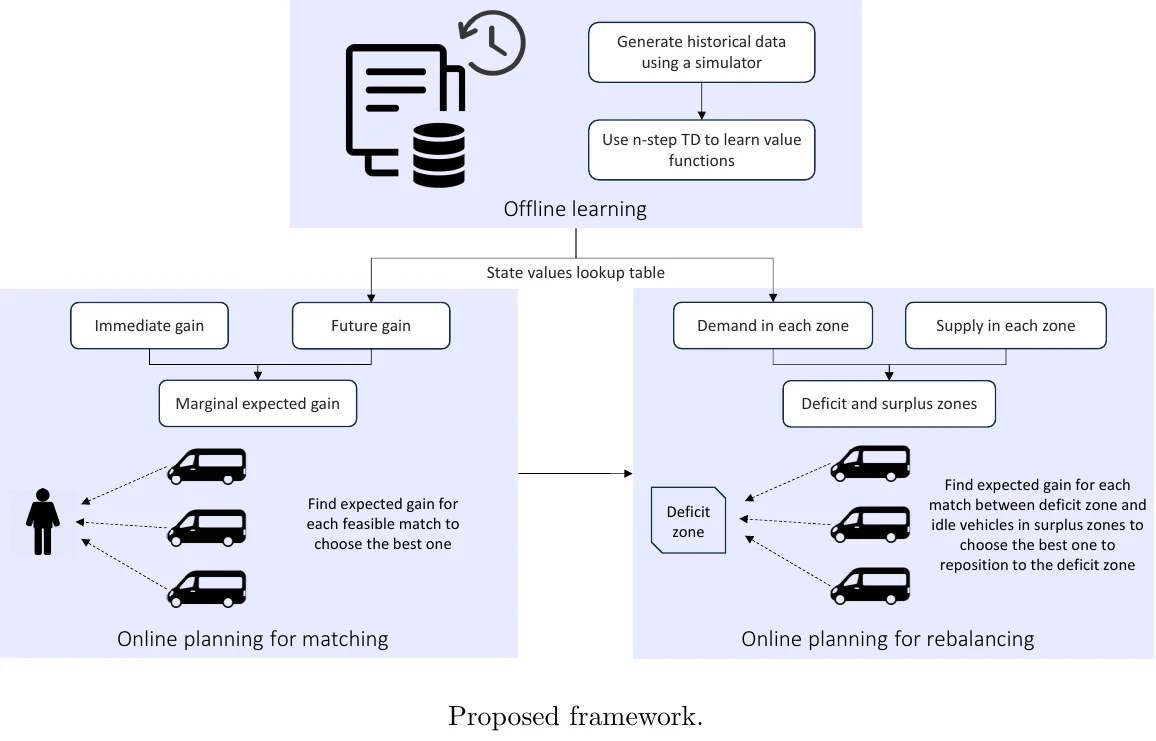
? 摘要翻译:拼车服务,也称为共享出行、共享叫车或微公交,是一种乘客共享乘车的服务。这种服务可以降低乘客和运营商的成本,减少拥堵和环境影响。然而,一个关键限制是其短视的决策制定,忽略了调度决策的长期影响。为了解决这个问题,我们提出了一种基于模拟的强化学习(RL)方法。虽然RL在叫车系统的研究中得到了广泛研究,但在拼车系统中的应用却相对较少。在本研究中,我们通过在学习机制中嵌入拼车模拟,将Xu等人(2018年)的学习和规划框架从叫车扩展到拼车,以实现非短视决策。此外,我们还提出了一种互补策略来重新平衡闲置车辆。通过在模拟经验上采用n步时间差分学习,我们推导出时空状态值,并随后使用纽约出租车请求数据评估非短视策略的有效性。结果表明,与短视策略相比,非短视匹配策略可以提高服务率高达8.4%,同时减少乘客在车内和等待的时间。此外,与短视策略相比,所提出的非短视策略可以将车队规模减少超过25%,同时保持相同水平的性能,从而为运营商提供显著的成本节约。将重新平衡操作纳入所提出的框架中,可以将等待时间减少高达27.3%,车内时间减少12.5%,并将服务率提高15.1%,但这是以每位乘客行驶的车辆分钟数增加为代价的。
? 本帖由AI整理生成,若有错误欢迎朱批!
?? 求一个关注,让我更有动力为大家整理更多的AI领域的新文章!
#LLM #NLP #AI #大模型 #人工智能 #论文阅读 #LLM翰林院
? 右滑查看士子奏报和论文重要图表——
?? 关注微臣,每天批阅更多奏章!
? 论文标题:Non-myopic Matching and Rebalancing in Large-Scale On-Demand Ride-Pooling Systems Using Simulation-Informed Reinforcement Learning
? Arxiv ID:2510.25796v1
? 关键词:ride-pooling, reinforcement learning, simulation, non-myopic decision-making, cost savings
? 太长不看版:该研究提出了一种基于模拟增强学习的拼车调度策略,有效提高了服务效率并降低运营成本。
? 摘要翻译:拼车服务,也称为共享出行、共享叫车或微公交,是一种乘客共享乘车的服务。这种服务可以降低乘客和运营商的成本,减少拥堵和环境影响。然而,一个关键限制是其短视的决策制定,忽略了调度决策的长期影响。为了解决这个问题,我们提出了一种基于模拟的强化学习(RL)方法。虽然RL在叫车系统的研究中得到了广泛研究,但在拼车系统中的应用却相对较少。在本研究中,我们通过在学习机制中嵌入拼车模拟,将Xu等人(2018年)的学习和规划框架从叫车扩展到拼车,以实现非短视决策。此外,我们还提出了一种互补策略来重新平衡闲置车辆。通过在模拟经验上采用n步时间差分学习,我们推导出时空状态值,并随后使用纽约出租车请求数据评估非短视策略的有效性。结果表明,与短视策略相比,非短视匹配策略可以提高服务率高达8.4%,同时减少乘客在车内和等待的时间。此外,与短视策略相比,所提出的非短视策略可以将车队规模减少超过25%,同时保持相同水平的性能,从而为运营商提供显著的成本节约。将重新平衡操作纳入所提出的框架中,可以将等待时间减少高达27.3%,车内时间减少12.5%,并将服务率提高15.1%,但这是以每位乘客行驶的车辆分钟数增加为代价的。
? 本帖由AI整理生成,若有错误欢迎朱批!
?? 求一个关注,让我更有动力为大家整理更多的AI领域的新文章!
#LLM #NLP #AI #大模型 #人工智能 #论文阅读 #LLM翰林院
